1 Appendix (cont). - Modeling Code¶
import pandas as pd
import numpy as np
import json
import os
import matplotlib.pyplot as plt
import seaborn as sns
import plotly as ply
from sklearn.preprocessing import OneHotEncoder, OrdinalEncoder, LabelEncoder, \
StandardScaler, Normalizer
from sklearn.model_selection import train_test_split, cross_val_score, KFold
from sklearn.metrics import confusion_matrix, accuracy_score, classification_report
from sklearn.decomposition import PCA
from sklearn import metrics, linear_model, tree
from sklearn.linear_model import BayesianRidge
from sklearn.naive_bayes import GaussianNB
import tensorflow as tf
from tensorflow.keras.layers import Dense, InputLayer, Dropout
from tensorflow.keras import Model, Sequential
import pydotplus
from IPython.display import Image
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis, \
LinearDiscriminantAnalysis
from sklearn.ensemble import GradientBoostingClassifier, RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
# Enable Experimental
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import SimpleImputer, IterativeImputer
import warnings
warnings.filterwarnings("ignore")
coupons_df = pd.read_csv('https://archive.ics.uci.edu/ml/\
machine-learning-databases/00603/in-vehicle-coupon-recommendation.csv')
coupons_df.head()
2 Preprocessing¶
# define columns types
nom = ['destination', 'passenger', 'weather', 'coupon',
'gender', 'maritalStatus', 'occupation']
bin = ['gender', 'has_children', 'toCoupon_GEQ15min',
'toCoupon_GEQ25min', 'direction_same']
ord = ['temperature', 'age', 'education', 'income',
'Bar', 'CoffeeHouse', 'CarryAway', 'RestaurantLessThan20',
'Restaurant20To50']
num = ['time', 'expiration']
ex = ['car', 'toCoupon_GEQ5min', 'direction_opp']
# Convert time to 24h military time
def convert_time(x):
if x[-2:] == "AM":
return int(x[0:-2]) % 12
else:
return (int(x[0:-2]) % 12) + 12
def average_income(x):
inc = np.array(x).astype(np.float)
return sum(inc) / len(inc)
def pre_process(df):
# keep original dataframe imutable
ret = df.copy()
# Drop columns
ret.drop(columns=['car', 'toCoupon_GEQ5min', 'direction_opp'],
inplace=True)
# rename values
ret = ret.rename(columns={'passanger':'passenger'})
ret['time'] = ret['time'].apply(convert_time)
ret['expiration'] = ret['expiration'].map({'1d':24, '2h':2})
# convert the following columns to ordinal values
ord_cols = ['Bar', 'CoffeeHouse', 'CarryAway', 'RestaurantLessThan20',
'Restaurant20To50']
ret[ord_cols] = ret[ord_cols].replace({'never': 0, 'less1': 1,
'1~3': 2, '4~8': 3, 'gt8': 4})
# impute missing
ret[ord_cols] = SimpleImputer(missing_values=np.nan,
strategy='most_frequent').fit_transform(ret[ord_cols])
# Changing coupon expiration to uniform # of hours
ret['expiration'] = coupons_df['expiration'].map({'1d':24, '2h':2})
# Age, Education, Income as ordinal
ret['age'] = ret['age'].map({'below21':1,
'21':2,'26':3,
'31':4,'36':5,
'41':6,'46':6,
'50plus':7})
ret['education'] = ret['education'].map(\
{'Some High School':1,
'Some college - no degree':2,
'Bachelors degree':3, 'Associates degree':4,
'High School Graduate':5,
'Graduate degree (Masters or Doctorate)':6})
ret['average income'] = ret['income'].str.findall('(\d+)').apply(average_income)
ret['income'].replace({'Less than $12500': 1, '$12500 - $24999': 2,
'$25000 - $37499': 3, '$37500 - $49999': 4,
'$50000 - $62499': 5, '$62500 - $74999': 6,
'$75000 - $87499': 7, '$87500 - $99999': 8,
'$100000 or More': 9}, inplace=True)
# Change gender to binary value
ret['gender'].replace({'Male': 0, 'Female': 1}, inplace=True)
# One Hot Encode
nom = ['destination', 'passenger', 'weather', 'coupon',
'maritalStatus', 'occupation']
for col in nom:
# k-1 cols from k values
ohe_cols = pd.get_dummies(ret[col], prefix=col, drop_first=True)
ret = pd.concat([ret, ohe_cols], axis=1)
ret.drop(columns=[col], inplace=True)
return ret
# Simple function to prep a dataframe for a model
def scale_data(df, std, norm, pass_cols):
"""
df: raw dataframe you want to process
std: list of column names you want to standardize (0 mean unit variance)
norm: list of column names you want to normalize (min-max)
pass_cols: list of columns that do not require processing (target var, etc.)
returns: prepped dataframe
"""
ret = df.copy()
# Only include columns from lists
ret = ret[std + norm + pass_cols]
# Standardize scaling for gaussian features
if (isinstance(std, list)) and (len(std) > 0):
ret[std] = StandardScaler().fit(ret[std]).transform(ret[std])
# Normalize (min-max) [0,1] for non-gaussian features
if (isinstance(norm, list)) and (len(norm) > 0):
ret[norm] = Normalizer().fit(ret[norm]).transform(ret[norm])
return ret
# Processed data (remove labels from dataset)
coupons_proc = pre_process(coupons_df.drop(columns='Y'))
# Labels
labels = coupons_df['Y']
# Standardize/Normalize
to_scale = ['average income', 'temperature', 'time', 'expiration']
coupons_proc = scale_data(coupons_proc, to_scale, [],
list(set(coupons_proc.columns.tolist()).difference(set(to_scale))))
coupons_proc.head()
Train/Test Split
X_train, X_test, y_train, y_test = train_test_split(coupons_proc, labels,
test_size=0.25,
random_state=42)
# Suppress info messages
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '1' # or any {'0', '1', '2'}
# learning rates
alphas = [0.0001, 0.001, 0.01, 0.1]
nn_models = []
nn_train_preds = []
nn_test_preds = []
for alpha in alphas:
nn_model = Sequential()
# nn_model.add(InputLayer(input_shape=(X_train.shape[1],)))
nn_model.add(Dropout(0.2, input_shape=(X_train.shape[1],)))
nn_model.add(Dense(64, activation='relu'))
nn_model.add(Dense(32, activation='relu'))
nn_model.add(Dense(16, activation='relu'))
nn_model.add(Dense(8, activation='relu'))
nn_model.add(Dense(4, activation='relu'))
nn_model.add(Dense(1, activation='sigmoid'))
nn_model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=alpha,
beta_1=0.9,
beta_2=0.999,
epsilon=1e-07,
amsgrad=False,
name='Adam')
, loss=tf.keras.losses.BinaryCrossentropy(), metrics=['accuracy'])
# nn_model.summary()
nn_model.fit(X_train.values, y_train.values, epochs=300, verbose=0)
# Store model
nn_models.append(nn_model)
nn_train_preds.append(nn_model.predict(X_train))
nn_test_preds.append(nn_model.predict(X_test))
train_acc = [metrics.accuracy_score(y_train, (nn_train_preds[i] >= 0.5) \
.astype(int)) for i in range(4)]
test_acc = [metrics.accuracy_score(y_test, (nn_test_preds[i] >= 0.5).\
astype(int)) for i in range(4)]
sns.lineplot(x=alphas, y=train_acc, label='Training Accuracy')
sns.lineplot(x=alphas, y=test_acc, label='Test Accuracy')
plt.title('Neural Network Accuracy by Learning Rate')
plt.xlabel('Learning Rate')
plt.ylabel('Accuracy')
plt.show()
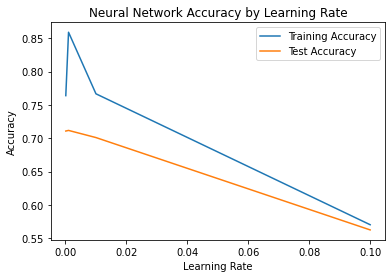
Based on the plot above, the optimal learning rate for the neural network os 0.001.
# Optimal Model predictions
nn_pred = nn_test_preds[1]
nn_roc = metrics.roc_curve(y_test, nn_pred)
nn_auc = metrics.auc(nn_roc[0], nn_roc[1])
# set true ositive rate, false positive rate, thresholds
fpr, tpr, thresholds = metrics.roc_curve(y_test, nn_pred)
# set the parameters for the ROC Curve
nn_plot = metrics.RocCurveDisplay(fpr=fpr, tpr=tpr,
roc_auc=nn_auc,
estimator_name='Neural Network')
# plot the ROC Curve
fig, ax = plt.subplots()
fig.suptitle('ROC Curve - Neural Network')
plt.plot([0, 1], [0, 1], linestyle = '--', color = '#174ab0')
nn_plot.plot(ax)
plt.show()
# Optimal Threshold value
nn_opt = nn_roc[2][np.argmax(nn_roc[1] - nn_roc[0])]
print('Optimal Threshold %f' % nn_opt)
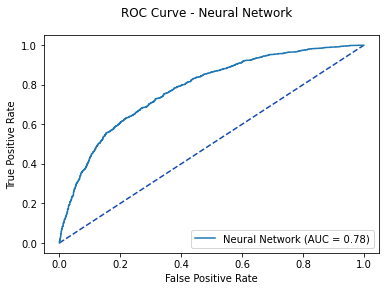
The optimized Neural Network predictions are further optimized based on the ROC Curve, defining the optimal probability threshold of 0.57
nn_cfm = metrics.confusion_matrix(y_test, (nn_pred >= nn_opt).astype(int))
sns.heatmap(nn_cfm, annot=True, fmt='g')
plt.title('Neural Network: Confusion Matrix - Test Data')
plt.show()
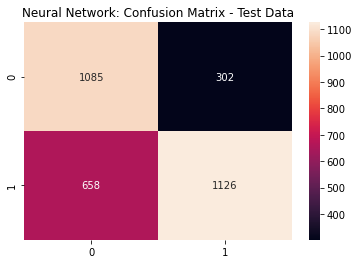
Neural Network Metrics
print(metrics.classification_report(y_test,
(nn_pred >= nn_opt).astype(int)))
3.2 Linear Discriminant Analysis¶
lda_model = LinearDiscriminantAnalysis().fit(X_train, y_train)
lda_cv = cross_val_score(lda_model, X_train, y_train)
print('LDA 5-fold Cross Validation Average %f' % lda_cv.mean())
# extract predicted probabilities from the model
lda_pred = lda_model.predict_proba(X_test)[:, 1]
# gather metrics
lda_roc = metrics.roc_curve(y_test, lda_pred)
lda_auc = metrics.auc(lda_roc[0], lda_roc[1])
# determine false positive rate, true positive rate, threshold
fpr, tpr, thresholds = metrics.roc_curve(y_test, lda_pred)
# set up the plot
lda_plot = metrics.RocCurveDisplay(fpr=fpr, tpr=tpr,
roc_auc=lda_auc, estimator_name='Linear Discriminant Analysis')
# make the plot
fig, ax = plt.subplots()
fig.suptitle('ROC Curve - LDA')
plt.plot([0, 1], [0, 1], linestyle = '--', color = '#174ab0')
lda_plot.plot(ax)
plt.show()
# Optimal Threshold value
lda_opt = lda_roc[2][np.argmax(lda_roc[1] - lda_roc[0])]
print('Optimal Threshold %f' % lda_opt)
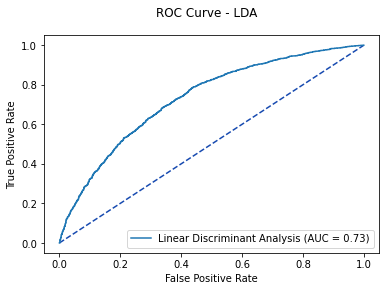
Based on the ROC Curve the optimal probability threshold for the trained LDA model is 0.496
lda_cfm = metrics.confusion_matrix(y_test, (lda_pred >= lda_opt).astype(int))
sns.heatmap(lda_cfm, annot=True, fmt='g')
plt.title('LDA Confusion Matrix - Test Data')
plt.show()
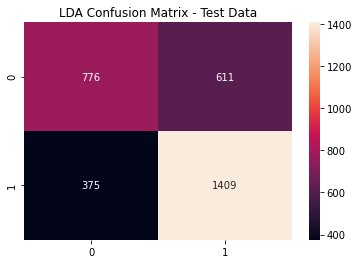
LDA Metrics
print(metrics.classification_report(y_test,
(lda_pred >= lda_opt).astype(int)))
3.3 Quadratic Discriminant Analysis¶
qda_model = QuadraticDiscriminantAnalysis().fit(X_train, y_train)
qda_cv = cross_val_score(qda_model, X_train, y_train)
print('QDA 5-fold Cross Validation Average %f' % qda_cv.mean())
qda_pred = qda_model.predict_proba(X_test)[:, 1]
qda_roc = metrics.roc_curve(y_test, qda_pred)
qda_auc = metrics.auc(qda_roc[0], qda_roc[1])
fpr, tpr, thresholds = metrics.roc_curve(y_test, qda_pred)
qda_plot = metrics.RocCurveDisplay(fpr=fpr, tpr=tpr,
roc_auc=qda_auc, estimator_name='Quadratic Discriminant Analysis')
fig, ax = plt.subplots()
fig.suptitle('ROC Curve - QDA')
plt.plot([0, 1], [0, 1], linestyle = '--', color = '#174ab0')
qda_plot.plot(ax)
plt.show()
# Optimal Threshold value
qda_opt = qda_roc[2][np.argmax(qda_roc[1] - qda_roc[0])]
print('Optimal Threshold %f' % qda_opt)
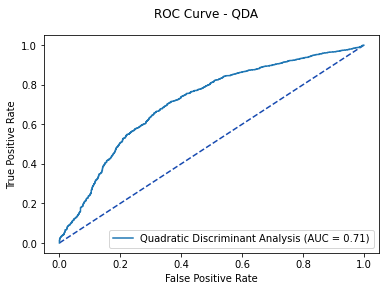
Based on the ROC Curve, the QDA Model has an optimal probability threshold of 0.463
qda_cfm = metrics.confusion_matrix(y_test,
(qda_pred >= qda_opt).astype(int))
sns.heatmap(qda_cfm,
annot=True, fmt='g')
plt.title('QDA Confusion Matrix - Test Data')
plt.show()
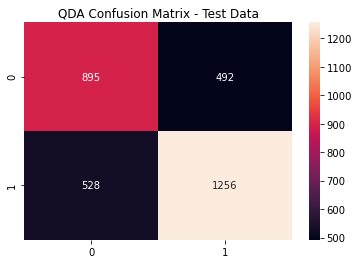
QDA Metrics
print(metrics.classification_report(y_test,
(qda_pred >= lda_opt).astype(int)))
3.4 Gradient Boosting¶
estimators = [50, 100, 250, 500]
depths = [1, 5, 10, 15]
fig, ax = plt.subplots(nrows=2, ncols=2, figsize=(15,15))
axes = ax.flatten()
k = 0
for i in estimators:
train_scores = []
test_scores = []
for j in depths:
gb_model = GradientBoostingClassifier(n_estimators=i,
learning_rate=1.0,
max_depth=j,
random_state=42).fit\
(X_train, y_train)
train_scores.append(cross_val_score(gb_model, X_train, y_train,
scoring='accuracy',
n_jobs=2).mean())
test_scores.append(metrics.accuracy_score(y_test,
gb_model.predict(X_test)))
sns.lineplot(x=depths, y=train_scores, label='Training Accuracy',
ax=axes[k])
sns.lineplot(x=depths, y=test_scores, label='Test Accuracy', ax=axes[k])
axes[k].set_title('Estimators: %d' % i)
axes[k].set_xlabel('Max Depth')
axes[k].set_ylabel('Accuracy')
k += 1
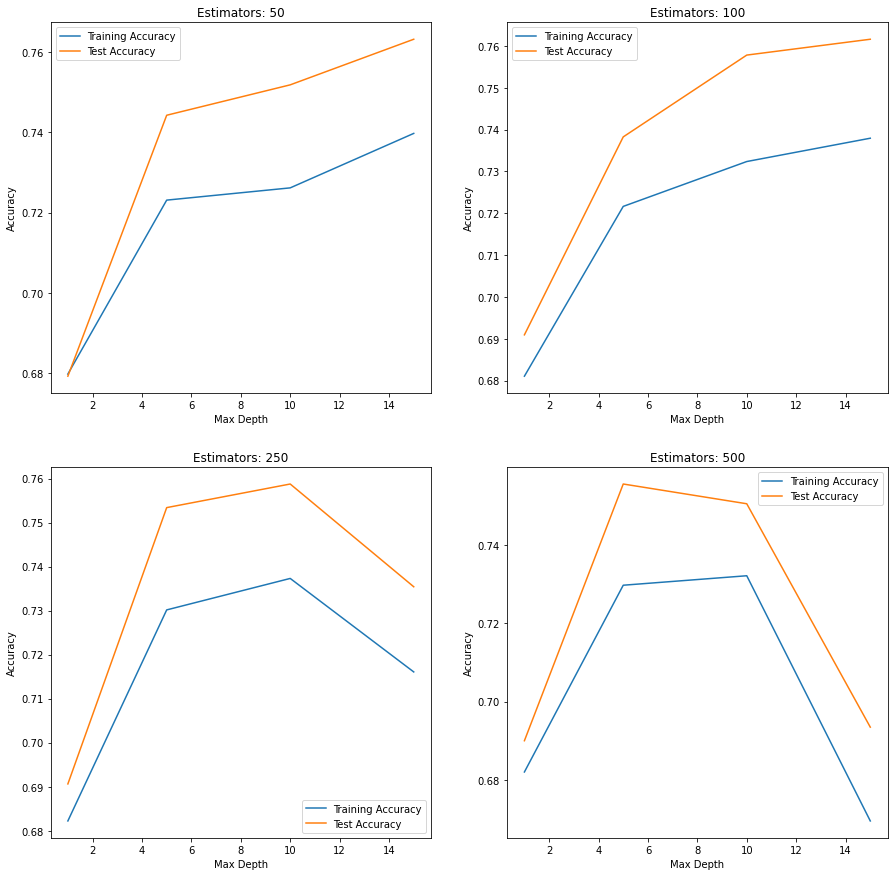
Based on the plots above, the Gradient Boosting Model with 500 trees with a max depth of 15, scored the highest overall test data accuracy.
# Optimal parameters 500 estimators, max_depth = 15
gb_model = GradientBoostingClassifier(n_estimators=500, learning_rate=1.0,
max_depth=15,
random_state=42).fit(X_train, y_train)
gb_pred = gb_model.predict_proba(X_test)[:, 1]
gb_roc = metrics.roc_curve(y_test, gb_pred)
gb_auc = metrics.auc(gb_roc[0], gb_roc[1])
fpr, tpr, thresholds = metrics.roc_curve(y_test, gb_pred)
gb_plot = metrics.RocCurveDisplay(fpr=fpr, tpr=tpr, roc_auc=gb_auc,
estimator_name='Gradient Boosting')
fig, ax = plt.subplots()
fig.suptitle('ROC Curve - GBM')
plt.plot([0, 1], [0, 1], linestyle = '--', color = '#174ab0')
gb_plot.plot(ax)
plt.show()
# Optimal Threshold value
gb_opt = gb_roc[2][np.argmax(gb_roc[1] - gb_roc[0])]
# print('Optimal Threshold %f' % gb_opt)
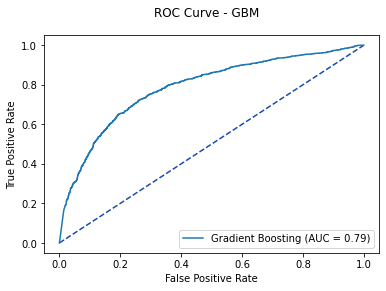
Based on the ROC Curve, the Gradient Boosting Model's optimal probability threshold is 0.361
gb_cfm = metrics.confusion_matrix(y_test, (gb_pred >= gb_opt).astype(int))
sns.heatmap(gb_cfm, annot=True, fmt='g')
plt.title('GBM Confusion Matrix - Test Data')
plt.show()
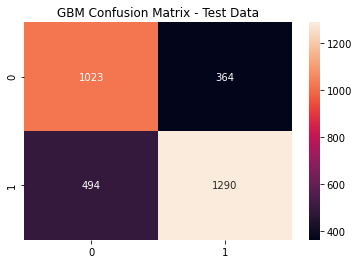
GBM Metrics
print(metrics.classification_report(y_test, (gb_pred >= gb_opt).astype(int)))
3.5 K-Nearest Neighbors¶
We look to K - nearest neighbors to determine the conditional probability Pr that a given target Y belongs to a class label j given that our feature space X is a matrix of observations xo.
We sum the k-nearest observations contained in a set N0 over an indicator variable I,thereby giving us a result of 0 or 1, dependent on class j.
Pr(Y=j|X=x0)=1k∑i∈N0I(yi=j)3.5.1 Euclidean Distance¶
Euclidean distance is used to measure the space between our input data and other data points in our feature space:
d(x,y)=√p∑i=1(xi−yi)2# euclidean distance
knn_train_accuracy = []
knn_test_accuracy = []
for n in range(1, 20) :
if(n%2!=0):
knn = KNeighborsClassifier(n_neighbors = n, p = 2)
knn = knn.fit(X_train,y_train)
knn_pred_train = knn.predict(X_train)
knn_pred_test = knn.predict(X_test)
knn_train_accuracy.append(accuracy_score(y_train, knn_pred_train))
knn_test_accuracy.append(accuracy_score(y_test, knn_pred_test))
print('# of Neighbors = %d \t Testing Accuracy = %2.2f \t \
Training Accuracy = %2.2f'% (n, accuracy_score(y_test,knn_pred_test),
accuracy_score(y_train,knn_pred_train)))
max_depth = list([1, 3, 5, 7, 9, 11, 13, 15, 17, 19])
plt.figure(figsize=(8,6))
plt.plot(max_depth, knn_train_accuracy, label='Training Accuracy')
plt.plot(max_depth, knn_test_accuracy, label='Test Accuracy')
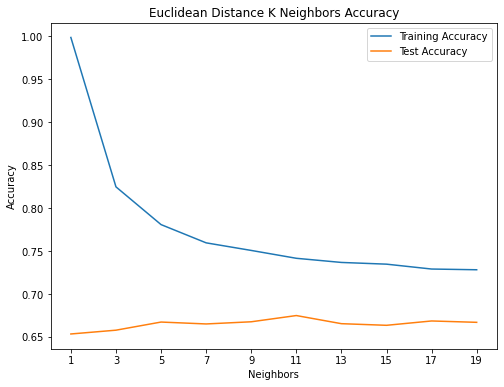
plt.title('Euclidean Distance K Neighbors Accuracy')
plt.xlabel('Neighbors')
plt.ylabel('Accuracy')
plt.xticks(max_depth)
plt.legend()
plt.show()
knn_pred = knn.predict_proba(X_test)[:, 1]
knn_roc = metrics.roc_curve(y_test, knn_pred_test)
knn_auc = metrics.auc(knn_roc[0], knn_roc[1])
fpr, tpr, thresholds = metrics.roc_curve(y_test, knn_pred)
knn_plot = metrics.RocCurveDisplay(fpr=fpr, tpr=tpr,
roc_auc=knn_auc, estimator_name='KNN - Euclidean Distance Model')
fig, ax = plt.subplots()
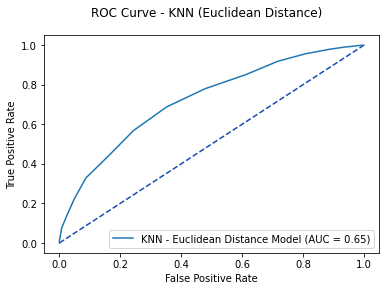
fig.suptitle('ROC Curve - KNN (Euclidean Distance)')
plt.plot([0, 1], [0, 1], linestyle = '--', color = '#174ab0')
knn_plot.plot(ax)
plt.show()
# Optimal Threshold value
knn_opt = knn_roc[2][np.argmax(knn_roc[1] - knn_roc[0])]
print('Optimal Threshold %f' % knn_opt)
metrics.accuracy_score(y_test, (knn_pred_test >= knn_opt).astype(int))
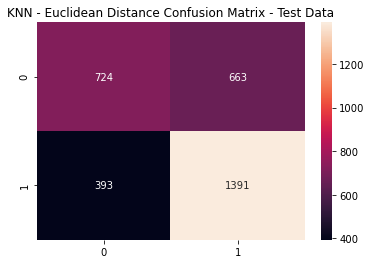
knn_cfm = metrics.confusion_matrix(y_test, (knn_pred_test >= knn_opt).astype(int))
sns.heatmap(knn_cfm, annot=True, fmt='g')
plt.title('KNN - Euclidean Distance Confusion Matrix - Test Data')
plt.show()
KNN: Euclidean Distance Metrics
print(metrics.classification_report(y_test,
(knn_pred_test >= knn_opt).astype(int)))
# k-nearest neighbor - KNN Manhattan Distance
numNeighbors = [1, 5, 11, 15, 21, 25, 31]
knn1_train_accuracy = []
knn1_test_accuracy = []
for k in numNeighbors:
knn1 = KNeighborsClassifier(n_neighbors=k, metric='manhattan', p=1)
knn1.fit(X_train, y_train)
knn1_pred_train = knn1.predict(X_train)
knn1_pred_test = knn1.predict(X_test)
knn1_train_accuracy.append(accuracy_score(y_train, knn1_pred_train))
knn1_test_accuracy.append(accuracy_score(y_test, knn1_pred_test))
print('# of Neighbors = %d \t Testing Accuracy %2.2f \t \
Training Accuracy %2.2f'% (k,accuracy_score(y_test,knn1_pred_test),
accuracy_score(y_train,knn1_pred_train)))
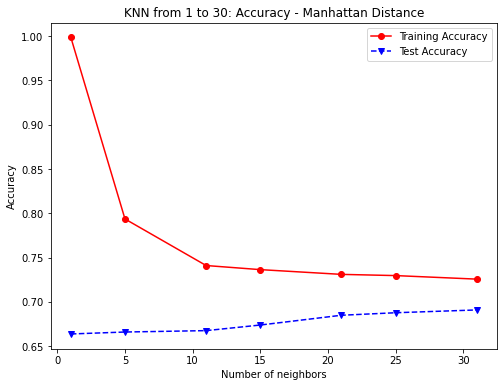
plt.figure(figsize=(8,6))
plt.plot(numNeighbors, knn1_train_accuracy, 'ro-',
numNeighbors, knn1_test_accuracy,'bv--')
plt.legend(['Training Accuracy','Test Accuracy'])
plt.title('KNN from 1 to 30: Accuracy - Manhattan Distance')
plt.xlabel('Number of neighbors')
plt.ylabel('Accuracy')
plt.show()
knn_pred1 = knn1.predict_proba(X_test)[:, 1]
knn1_roc = metrics.roc_curve(y_test, knn_pred1)
knn1_auc = metrics.auc(knn1_roc[0], knn1_roc[1])
fpr, tpr, thresholds = metrics.roc_curve(y_test, knn_pred1)
knn1_plot = metrics.RocCurveDisplay(fpr=fpr, tpr=tpr, roc_auc=knn1_auc,
estimator_name='KNN - Manhattan Distance Model')
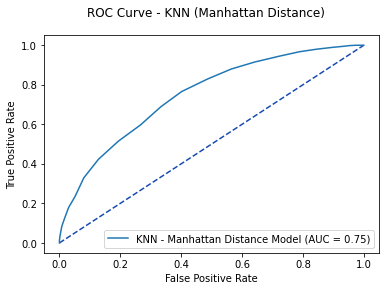
fig, ax = plt.subplots()
fig.suptitle('ROC Curve - KNN (Manhattan Distance)')
plt.plot([0, 1], [0, 1], linestyle = '--', color = '#174ab0')
knn1_plot.plot(ax)
plt.show()
# Optimal Threshold value
knn1_opt = knn1_roc[2][np.argmax(knn1_roc[1] - knn1_roc[0])]
print('Optimal Threshold %f' % knn1_opt)
metrics.accuracy_score(y_test, (knn1_pred_test >= knn1_opt).astype(int))
knn1_cfm = metrics.confusion_matrix(y_test, (knn1_pred_test >= knn1_opt).astype(int))
sns.heatmap(knn1_cfm, annot=True, fmt='g')
plt.title('KNN - Manhattan Distance Confusion Matrix - Test Data')
plt.show()

KNN: Manhattan Distance Metrics
print(metrics.classification_report(y_test,
(knn1_pred_test >= knn1_opt).astype(int)))
3.7 Random Forest Model¶
rf_train_accuracy = []
rf_test_accuracy = []
for n in range(1, 21):
rf = RandomForestClassifier(max_depth = n, random_state=42)
rf = rf.fit(X_train,y_train)
rf_pred_train = rf.predict(X_train)
rf_pred_test = rf.predict(X_test)
rf_train_accuracy.append(accuracy_score(y_train, rf_pred_train))
rf_test_accuracy.append(accuracy_score(y_test, rf_pred_test))
print('Max Depth = %2.0f \t Testing Accuracy = %2.2f \t \
Training Accuracy = %2.2f'% (n,accuracy_score(y_test,rf_pred_test),
accuracy_score(y_train,rf_pred_train)))
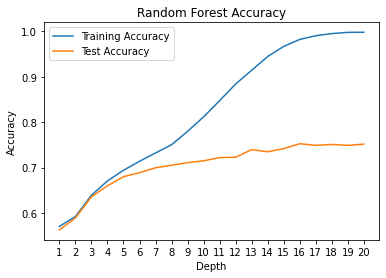
max_depth = list(range(1,21))
plt.plot(max_depth, rf_train_accuracy, label='Training Accuracy')
plt.plot(max_depth, rf_test_accuracy, label='Test Accuracy')
plt.title('Random Forest Accuracy')
plt.xlabel('Depth')
plt.ylabel('Accuracy')
plt.xticks(max_depth); plt.legend(); plt.show()
rf_model = RandomForestClassifier(max_depth = 16,
random_state = 42)
rf_model = rf_model.fit(X_train,y_train)
rf_model_pred_test = rf_model.predict(X_test)
rf_pred1 = rf.predict_proba(X_test)[:, 1]
rf_roc = metrics.roc_curve(y_test, rf_pred1)
rf_auc = metrics.auc(rf_roc[0], rf_roc[1])
fpr, tpr, thresholds = metrics.roc_curve(y_test, rf_pred1)
rf_plot = metrics.RocCurveDisplay(fpr=fpr, tpr=tpr,
roc_auc=rf_auc, estimator_name='Random Forest Model')
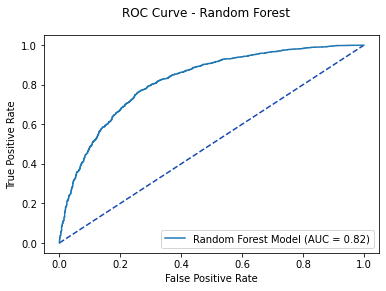
fig, ax = plt.subplots()
fig.suptitle('ROC Curve - Random Forest')
plt.plot([0, 1], [0, 1], linestyle = '--', color = '#174ab0')
rf_plot.plot(ax)
plt.show()
# Optimal Threshold value
rf_opt = rf_roc[2][np.argmax(rf_roc[1] - rf_roc[0])]
print('Optimal Threshold %f' % rf_opt)
metrics.accuracy_score(y_test, (rf_model_pred_test >= rf_opt).astype(int))
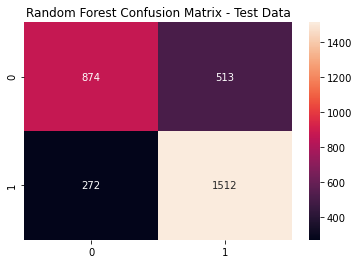
rf_cfm = metrics.confusion_matrix(y_test, (rf_model_pred_test >= rf_opt).astype(int))
sns.heatmap(rf_cfm, annot=True, fmt='g')
plt.title('Random Forest Confusion Matrix - Test Data'); plt.show()
Random Forest Metrics
print(metrics.classification_report(y_test,
(rf_model_pred_test >= rf_opt).astype(int)))
3.8 Naive Bayes¶
nb_model = GaussianNB()
nb_model = nb_model.fit(X_train, y_train)
nb_model_pred_test = nb_model.predict(X_test)
nb_pred1 = nb_model.predict_proba(X_test)[:, 1]
nb_roc = metrics.roc_curve(y_test,
nb_model_pred_test)
nb_auc = metrics.auc(nb_roc[0], nb_roc[1])
fpr, tpr, thresholds = metrics.roc_curve(y_test,
nb_pred1)
nb_plot = metrics.RocCurveDisplay(fpr=fpr,
tpr=tpr,
roc_auc=nb_auc,
estimator_name='Naive Bayes Model')
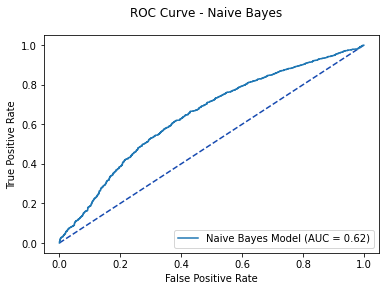
fig, ax = plt.subplots()
fig.suptitle('ROC Curve - Naive Bayes')
plt.plot([0, 1],
[0, 1],
linestyle = '--',
color = '#174ab0')
nb_plot.plot(ax)
plt.show()
# Optimal Threshold value
nb_opt = nb_roc[2][np.argmax(nb_roc[1] - nb_roc[0])]
print('Optimal Threshold %f' % nb_opt)
metrics.accuracy_score(y_test, (nb_model_pred_test >= nb_opt).astype(int))
nb_cfm = metrics.confusion_matrix(y_test, (nb_model_pred_test >= nb_opt).astype(int))
sns.heatmap(nb_cfm, annot=True, fmt='g')
plt.title('Naive Bayes Confusion Matrix - Test Data')
plt.show()
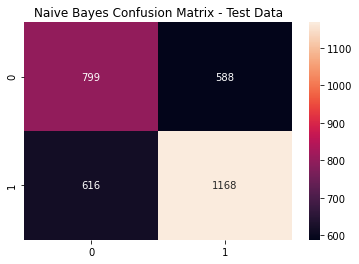
Naive Bayes Metrics
print(metrics.classification_report(y_test,
(nb_model_pred_test >= nb_opt).astype(int)))
3.9 Tuned Decision Tree Classifier¶
coupon_tree2 = tree.DecisionTreeClassifier(max_depth=3,
max_features=56,
random_state=42)
coupon_tree2 = coupon_tree2.fit(X_train,y_train)
coupon_pred2 = coupon_tree2.predict(X_test)
print('accuracy = %2.2f ' % accuracy_score(y_test,
coupon_pred2))
print(classification_report(y_test, coupon_pred2))
3.9.1 Plotting the Decision Tree¶
dot_data = tree.export_graphviz(coupon_tree2,
feature_names=coupons_proc.columns,
filled=True,
out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
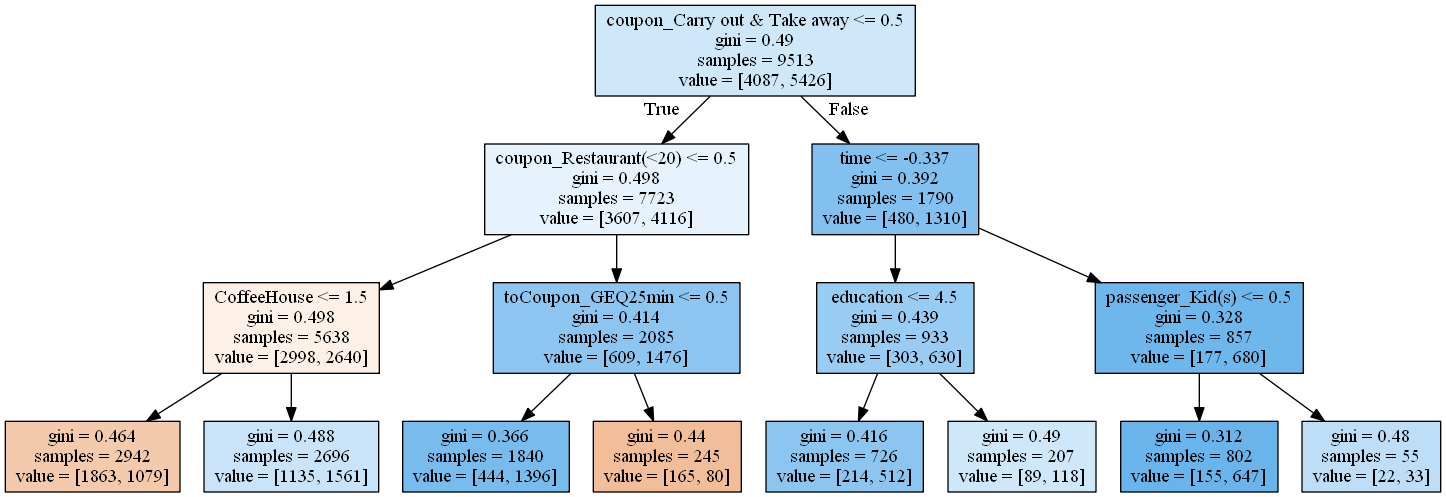
3.9.2 Decision Tree Tuning (Varying Max-Depth from 3 to 10)¶
accuracy_depth = []
# Vary the decision tree depth in a loop, increasing depth from 3 to 10.
for depth in range(3,11):
varied_tree = tree.DecisionTreeClassifier(max_depth=depth, random_state=42)
varied_tree = varied_tree.fit(X_train,y_train)
tree_pred = varied_tree.predict(X_test)
tree_train_pred = varied_tree.predict(X_train)
accuracy_depth.append({'depth':depth,
'test_accuracy':accuracy_score(y_test,tree_pred),
'train_accuracy':accuracy_score(y_train,tree_train_pred)})
print('Depth = %2.0f \t Testing Accuracy = %2.2f \t \
Training Accuracy = %2.2f'% (depth,accuracy_score(y_test,tree_pred),
accuracy_score(y_train,tree_train_pred)))
abd_df = pd.DataFrame(accuracy_depth)
abd_df.index = abd_df['depth']
fig, ax=plt.subplots(figsize=(8,6))
ax.plot(abd_df.depth,abd_df.train_accuracy,'ro-',label='Training Error')
ax.plot(abd_df.depth,abd_df.test_accuracy,'bv--',label='Testing Error')
plt.title('Varied Tree Depth')
ax.set_xlabel('Max Depth')
ax.set_ylabel('Accuracy')
plt.legend()
plt.show()
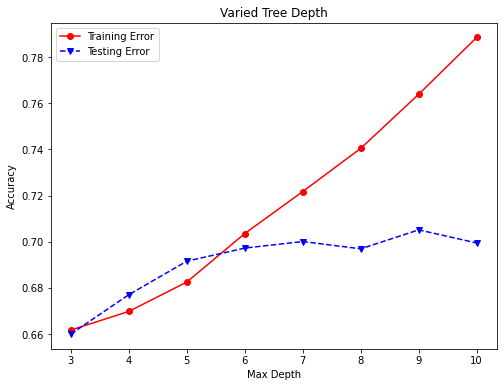
varied_tree_roc = metrics.roc_curve(y_test, tree_pred)
varied_tree_auc = metrics.auc(varied_tree_roc[0], varied_tree_roc[1])
varied_tree1 = varied_tree.predict_proba(X_test)[: ,1]
fpr, tpr, thresholds = metrics.roc_curve(y_test, varied_tree1)
varied_tree_plot = metrics.RocCurveDisplay(fpr=fpr, tpr=tpr,
roc_auc = varied_tree_auc,
estimator_name='Tuned Decision Tree Model')
fig, ax = plt.subplots()
fig.suptitle('ROC Curve - Tuned Decision Tree')
plt.plot([0, 1], [0, 1], linestyle = '--', color = '#174ab0')
varied_tree_plot.plot(ax)
plt.show()
# Optimal Threshold value
varied_tree_opt = varied_tree_roc[2][np.argmax(
varied_tree_roc[1]-varied_tree_roc[0])]
print('Optimal Threshold %f' % varied_tree_opt)
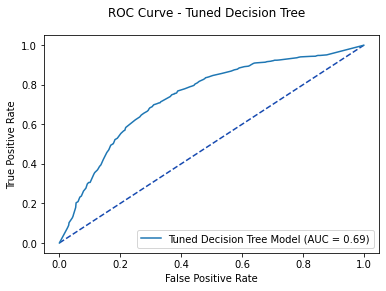
metrics.accuracy_score(y_test, (tree_pred >= varied_tree_opt).astype(int))
tlr_cfm = metrics.confusion_matrix(y_test, (tree_pred >= varied_tree_opt).astype(int))
sns.heatmap(tlr_cfm, annot=True, fmt='g')
plt.title('Tuned Decision Tree Confusion Matrix - Test Data')
plt.show()

Tuned Decision Tree Metrics
print(metrics.classification_report(y_test, (tree_pred >= varied_tree_opt).astype(int)))
3.10 Tuned Logistic Regression Model¶
We hereby tune our logistic regression model as follows. Using a linear classifier, the model is able to create a linearly separable hyperplane bounded by the class of observations from our preprocessed coupon dataset and the likelihood of occurrences within the class.
The descriptive form of the ensuing logistic regression is shown below: P(y=1|x)=11+exp−wTx−b=σ(wTx+b)
The model is further broken down into an optimization function of the regularized negative log-likelihood, where w and b are estimated parameters.
(w∗,b∗)=argminw,b−N∑i=1yilog[σ(wTxi+b)]+(1−yi)log[σ(−wTxi−b)]+1CΩ([w,b])Herein, we further tune our cost hyperparamter C, such that the model complexity is varied (regularized by Ω(⋅)) from smallest to largest, producing a greater propensity for classification accuracy at each iteration.
Moreover, we rely on the default l2-norm to pair with the lbfgs solver, and cap off our max iterations at 2,000 such that the model does not fail to converge.
C = [0.01, 0.1, 0.2, 0.5, 0.8, 1, 5, 10, 20, 50]
LRtrainAcc = []
LRtestAcc = []
for param in C:
tlr = linear_model.LogisticRegression(penalty='l2',
solver = 'lbfgs',
max_iter= 2000,
C=param, random_state=42)
tlr.fit(X_train, y_train)
tlr_pred_train = tlr.predict(X_train)
tlr_pred_test = tlr.predict(X_test)
LRtrainAcc.append(accuracy_score(y_train, tlr_pred_train))
LRtestAcc.append(accuracy_score(y_test, tlr_pred_test))
print('Cost = %2.2f \t Testing Accuracy = %2.2f \t \
Training Accuracy = %2.2f'% (param,accuracy_score(y_test,tlr_pred_test),
accuracy_score(y_train,tlr_pred_train)))
fig, ax = plt.subplots()
ax.plot(C, LRtrainAcc, 'ro-', C, LRtestAcc,'bv--')
ax.legend(['Training Accuracy','Test Accuracy'])
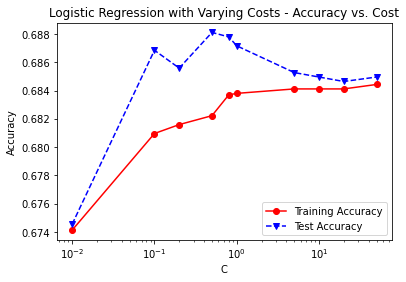
plt.title('Logistic Regression with Varying Costs - Accuracy vs. Cost')
ax.set_xlabel('C')
ax.set_xscale('log')
ax.set_ylabel('Accuracy')
plt.show()
tlr_roc = metrics.roc_curve(y_test, tlr_pred_test)
tlr_auc = metrics.auc(tlr_roc[0], tlr_roc[1])
tlr1 = tlr.predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = metrics.roc_curve(y_test, tlr1)
tlr_plot = metrics.RocCurveDisplay(fpr=fpr, tpr=tpr,
roc_auc=tlr_auc, estimator_name='Tuned Logisitc Regression Model')
fig, ax = plt.subplots(figsize=(8,5))
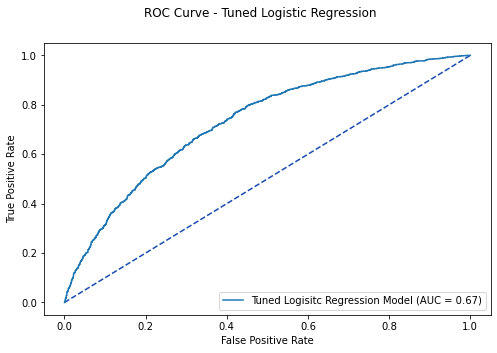
fig.suptitle('ROC Curve - Tuned Logistic Regression')
plt.plot([0, 1], [0, 1], linestyle = '--', color = '#174ab0')
tlr_plot.plot(ax)
plt.show()
# Optimal Threshold value
tlr_opt = tlr_roc[2][np.argmax(tlr_roc[1] - tlr_roc[0])]
print('Optimal Threshold %f' % tlr_opt)
metrics.accuracy_score(y_test, (tlr_pred_test >= tlr_opt).astype(int))
tlr_cfm = metrics.confusion_matrix(y_test, (tlr_pred_test >= tlr_opt).astype(int))
sns.heatmap(tlr_cfm, annot=True, fmt='g')
plt.title('Tuned Logistic Regression Confusion Matrix - Test Data')
plt.show()

Tuned Logistic Regression Metrics
print(metrics.classification_report(y_test, (tlr_pred_test >= tlr_opt).astype(int)))
3.11 Support Vector Machines¶
Similar to that of logistic regression, a linear support vector machine model relies on estimating (w∗,b∗) visa vie constrained optimization of the following form: minw∗,b∗,{ξi}‖w‖22+1C∑iξis.t.∀i:yi[wTϕ(xi)+b]≥1−ξi, ξi≥0
However, our endeavor relies on the radial basis function kernel:
K(x,x′)=exp(−||x−x′||22σ2)where ||x−x′||2 is the squared Euclidean distance between the two feature vectors, and γ=12σ2.
Simplifying the equation we have:
K(x,x′)=exp(−γ||x−x′||2)3.12 SVM (Radial Basis Function) Model¶
3.12.1 Untuned Support Vector Machine¶
svm1 = SVC(kernel='rbf', random_state=42)
svm1.fit(X_train, y_train)
svm1_pred_test = svm1.predict(X_test)
print('accuracy = %2.2f ' % accuracy_score(y_test, svm1_pred_test))
3.12.2 Setting (tuning) the gamma hyperparameter to "auto"¶
svm2 = SVC(kernel='rbf', gamma='auto', random_state=42)
svm2.fit(X_train, y_train)
svm2_pred_test = svm2.predict(X_test)
print('accuracy = %2.2f ' % accuracy_score(svm2_pred_test,y_test))
3.12.3 Tuning the support vector machine over 10 values of the cost hyperparameter¶
C = [0.01, 0.1, 0.2, 0.5, 0.8, 1, 5, 10, 20, 50]
svm3_trainAcc = []
svm3_testAcc = []
for param in C:
svm3 = SVC(C=param,kernel='rbf', gamma = 'auto', random_state=42,
probability=True)
svm3.fit(X_train, y_train)
svm3_pred_train = svm3.predict(X_train)
svm3_pred_test = svm3.predict(X_test)
svm3_trainAcc.append(accuracy_score(y_train, svm3_pred_train))
svm3_testAcc.append(accuracy_score(y_test, svm3_pred_test))
print('Cost = %2.2f \t Testing Accuracy = %2.2f \t \
Training Accuracy = %2.2f'% (param,accuracy_score(y_test,svm3_pred_test),
accuracy_score(y_train,svm3_pred_train)))
fig, ax = plt.subplots()
ax.plot(C, svm3_trainAcc, 'ro-', C, svm3_testAcc,'bv--')
ax.legend(['Training Accuracy','Test Accuracy'])
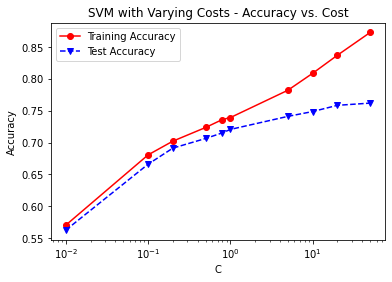
plt.title('SVM with Varying Costs - Accuracy vs. Cost')
ax.set_xlabel('C')
ax.set_xscale('log')
ax.set_ylabel('Accuracy')
plt.show()
svm3_roc = metrics.roc_curve(y_test, svm3_pred_test)
svm3_auc = metrics.auc(svm3_roc[0], svm3_roc[1])
svm3_pred = svm3.predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = metrics.roc_curve(y_test, svm3_pred)
svm3_plot = metrics.RocCurveDisplay(fpr=fpr, tpr=tpr,
roc_auc=svm3_auc, estimator_name='Support Vector Machines')
fig, ax = plt.subplots()
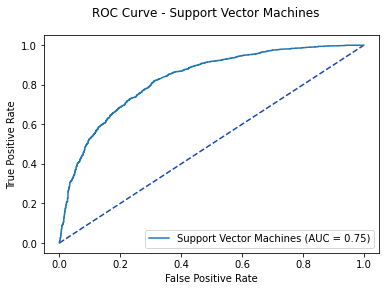
fig.suptitle('ROC Curve - Support Vector Machines')
plt.plot([0, 1], [0, 1], linestyle = '--', color = '#174ab0')
svm3_plot.plot(ax)
plt.show()
# Optimal Threshold value
svm3_opt = svm3_roc[2][np.argmax(svm3_roc[1] - svm3_roc[0])]
print('Optimal Threshold %f' % svm3_opt)
metrics.accuracy_score(y_test, (svm3_pred_test >= svm3_opt).astype(int))
svm3_cfm = metrics.confusion_matrix(y_test, (svm3_pred_test >= svm3_opt).astype(int))
sns.heatmap(svm3_cfm, annot=True, fmt='g')
plt.title('Support Vector Machines Confusion Matrix - Test Data'); plt.show()

print(metrics.classification_report(y_test,
(svm3_pred_test >= svm3_opt).astype(int)))
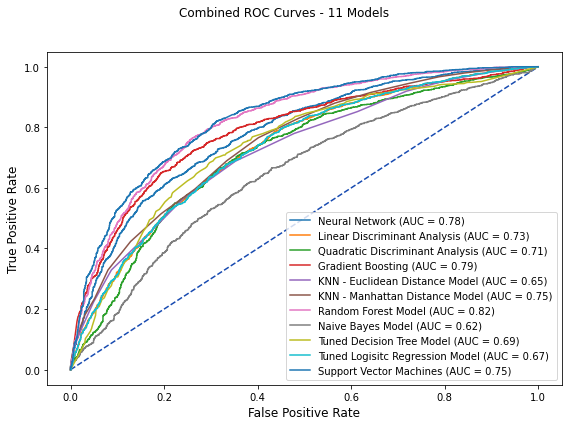
4 Combined ROC Curves¶
fig, ax = plt.subplots(figsize=(8, 6))
fig.suptitle('Combined ROC Curves - 11 Models')
plt.plot([0, 1], [0, 1], linestyle = '--', color = '#174ab0')
plt.xlabel('',fontsize=12)
plt.ylabel('',fontsize=12)
# Model ROC Plots Defined above
# neural network
nn_plot.plot(ax)
# linear discriminant analysis
lda_plot.plot(ax)
# quadratic discriminant analysis
qda_plot.plot(ax)
# gradient boosting
gb_plot.plot(ax)
# k-nearest neighbors euclidean distance
knn_plot.plot(ax)
# k-nearest neighbors manhattan distance
knn1_plot.plot(ax)
# random forest
rf_plot.plot(ax)
# naive bayes
nb_plot.plot(ax)
# tuned decision tree
varied_tree_plot.plot(ax)
# tuned logistic regression
tlr_plot.plot(ax)
# support vector machines
svm3_plot.plot(ax)
# set the plotting margins
plt.tight_layout(rect=[0, 0, 1, 0.9])
plt.show()