Predicting Cervical Cancer From Biopsy Results¶
Shpaner, Leonid - March 1, 2022
A thorough protocol for cervical cancer detection hinges on cytological tests in conjunction with other methodologies; The focus is narrowed to patients that are healthy vs. unhealthy (based on biopsy results). This predictive modeling endeavor stems from the selection of 858 female patients ages 13-84 from a Venezuelan inpatient clinic. The data is preprocessed; feature selection is based on removal of highly correlated and near zero variance predictors. The data is subsequently partitioned using an 80:20 train-test split ratio to evaluate the model performance of data outside the training set. The class imbalance scenario whereby the majority of cases (healthy) is rebalanced with oversampling. Three models are proposed to aide in establishing the likelihood of being diagnosed with cervical cancer. Results vary based on key performance indicators of the receiver operating characteristics’ areas under their curves. Furthermore, each model is holistically evaluated based on its predictive ability.
Keywords: cervical cancer, machine learning, ensemble methods, predictive modeling
Loading, Pre-Processing, and Exploring Data¶
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from prettytable import PrettyTable
from imblearn.over_sampling import SMOTE, ADASYN
from sklearn.decomposition import PCA
import statsmodels.api as sm
from sklearn.model_selection import train_test_split, \
RepeatedStratifiedKFold, RandomizedSearchCV
from sklearn import metrics
from sklearn.metrics import roc_curve, auc, mean_squared_error,\
precision_score, recall_score, f1_score, accuracy_score,\
confusion_matrix, plot_confusion_matrix, classification_report
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from scipy.stats import loguniform, uniform, truncnorm, randint
import warnings
warnings.filterwarnings('ignore')
url = 'https://raw.githubusercontent.com/lshpaner/\
MSADS_503_Predictive_Modeling_Predicting_Cervical_Cancer/main/\
code_files/risk_factors_cervical_cancer.csv'
Now, we proceed to read in the flat .csv file, and examine the first 5 rows of data.
df = pd.read_csv(url)
df.head()
# replace original dataframe's ? symbol with nulls
df = df.replace('?', np.nan)
Features' Data Types and Their Respective Null Counts¶
print('Number of Rows:', df.shape[0])
print('Number of Columns:', df.shape[1], '\n')
data_types = df.dtypes
data_types = pd.DataFrame(data_types)
data_types = data_types.assign(Null_Values =
df.isnull().sum())
total_null = data_types['Null_Values'].sum()
data_types.reset_index(inplace = True)
data_types = data_types.rename(columns={0:'Data Type',
'index': 'Column/Variable',
'Null_Values': "# of Nulls"})
data_types
print ('Total # of Missing Values:', total_null)
The following columns have #NA values
df.columns[df.isnull().any()].tolist()
# drop columns with tests other than Biopsy
cervdat = df.drop(columns=['Citology', 'Schiller', 'Hinselmann'])
# nunmericize features
cervdat = cervdat.apply(pd.to_numeric)
cervdat.dtypes
# inspect number of rows, columns
print('Number of Rows:', cervdat.shape[0])
print('Number of Columns:', cervdat.shape[1], '\n')
Imputing Missing Values by Median¶
cervdat = cervdat.fillna(cervdat.median())
var = pd.DataFrame(cervdat.var())
var.reset_index(inplace = True)
var = var.rename(columns={0:'Variance',
'index': 'Column/Variable'})
var
# drop columns with near zero variance and get shape
cervdat = cervdat.drop(columns=['Smokes (years)', 'Smokes (packs/year)',
'IUD (years)', 'STDs:cervical condylomatosis',
'STDs:vaginal condylomatosis',
'STDs:syphilis', 'STDs:pelvic inflammatory disease',
'STDs:genital herpes', 'STDs:molluscum contagiosum',
'STDs:AIDS', 'STDs:HIV', 'STDs:Hepatitis B', 'STDs:HPV',
'STDs: Time since first diagnosis', 'Dx:Cancer', 'Dx:HPV',
'Dx'])
cervdat.shape
# encode target to categorical variable
cervdat['Biopsy_Res'] = np.where(cervdat['Biopsy'] > 0, 'Cancer', 'Healthy')
# create dictionary for age ranges
cervdat['Age_Range'] = cervdat['Age'].map({13:'13-17', 14:'13-17',
15: '13-17', 16:'13-17', 17: '13-17', 18: '18-21', 19: '18-21', 20: '18-21',
21: '18-21', 22: '22-30', 23: '22-30', 24: '22-30', 25: '22-30', 26: '22-30',
27: '22-30', 28: '22-30', 29: '22-30', 30: '22-30', 31: '31-40', 32: '31-40',
33: '31-40', 34: '31-40', 35: '31-40', 36: '31-40', 37: '31-40', 38: '31-40',
39: '31-40', 40: '31-40', 41: '41-50', 42: '41-50', 43: '41-50', 44: '41-50',
45: '41-50', 46: '41-50', 47: '41-50', 48: '41-50', 49: '41-50', 50: '41-50',
51: '51-60', 52: '51-60', 53: '51-60', 53: '51-60', 54: '51-60', 55: '51-60',
56: '51-60', 57: '51-60', 58: '51-60', 58: '51-60', 59: '51-60', 60: '51-60',
61: '61-70', 62: '61-70', 63: '61-70', 64: '61-70', 65: '61-70', 66: '61-70',
67: '61-70', 68: '61-70', 69: '61-70', 70: '61-70', 71: '71-80', 72: '71-80',
73: '71-80', 74: '71-80', 75: '71-80', 76: '71-80', 77: '71-80', 78: '71-80',
79: '71-80', 80: '71-80', 81: '81-90', 82: '81-90', 83: '81-90', 84: '81-90',
85: '81-90', 86: '81-90', 87: '81-90', 87: '81-90', 88: '81-90', 89: '81-90',
90: '81-90'})
Exploratory Data Analysis (EDA)¶
Distribution: Histograms¶
# checking for degenerate distributions
cervdat.hist(grid=False,
figsize=(16,16))
plt.show()
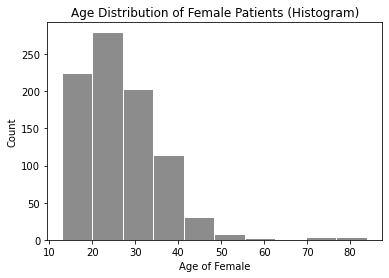
Selected Histogram - Age of Female¶
# age bar graph
plt.hist(cervdat['Age'], bins=10, color='gray', alpha=0.9, rwidth=.97)
plt.title('Age Distribution of Female Patients (Histogram)')
plt.xlabel('Age of Female')
plt.ylabel('Count')
plt.show()
Five Number Summary¶
# five number summary
age_summary = pd.DataFrame(cervdat['Age'].describe()).T
age_summary
print("\033[1m"+'Age Range Summary'+"\033[1m")
def cerv_stats_by_age():
pd.options.display.float_format = '{:,.2f}'.format
new2 = cervdat.groupby('Age_Range')['Age']\
.agg(["mean", "median", "std", "min", "max"])
new2.loc['Total'] = new2.sum(numeric_only=True, axis=0)
column_rename = {'mean': 'Mean', 'median': 'Median',
'std': 'Standard Deviation',\
'min':'Minimum','max': 'Maximum'}
dfsummary = new2.rename(columns = column_rename)
return dfsummary
cerv_stats_age = cerv_stats_by_age()
cerv_stats_by_age()
cerv_stats_age.iloc[:, 0:3][0:8].plot.barh(figsize=(8,3.5))
plt.show()
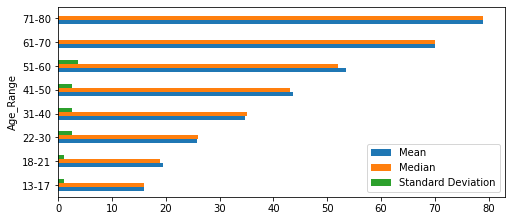
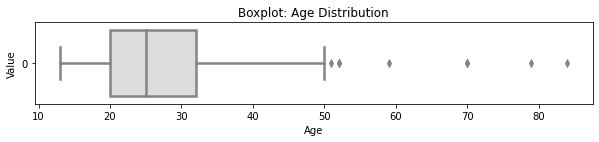
Boxplot¶
# selected boxplot distributions
print("\033[1m"+'Boxplot Distribution'+"\033[1m")
# Boxplot of age as one way of showing distribution
fig = plt.figure(figsize = (10,1.5))
plt.title ('Boxplot: Age Distribution')
plt.xlabel('Age')
plt.ylabel('Value')
sns.boxplot(data=cervdat['Age'],
palette="coolwarm", orient='h',
linewidth=2.5)
plt.show()
IQR = age_summary['75%'][0] - age_summary['25%'][0]
print('The first quartile is %s. '%age_summary['25%'][0])
print('The third quartile is %s. '%age_summary['75%'][0])
print('The IQR is %s.'%round(IQR,2))
print('The mean is %s. '%round(age_summary['mean'][0],2))
print('The standard deviation is %s. '%round(age_summary['std'][0],2))
print('The median is %s. '%round(age_summary['50%'][0],2))
Contingency Table¶
def age_biopsy():
Biopsy_Res_healthy = cervdat.loc[cervdat.Biopsy_Res == 'Healthy'].groupby(
['Age_Range'])[['Biopsy_Res']].count()
Biopsy_Res_healthy.rename(columns = {'Biopsy_Res':'Healthy'}, inplace=True)
Biopsy_Res_cancer= cervdat.loc[cervdat.Biopsy_Res == 'Cancer'].groupby(
['Age_Range'])[['Biopsy_Res']].count()
Biopsy_Res_cancer.rename(columns = {'Biopsy_Res':'Cancer'}, inplace=True)
Biopsy_Res_comb = pd.concat([Biopsy_Res_healthy, Biopsy_Res_cancer], axis=1)
# sum row totals
Biopsy_Res_comb['Total']=Biopsy_Res_comb.sum(axis=1)
Biopsy_Res_comb.loc['Total']=Biopsy_Res_comb.sum(numeric_only=True, axis=0)
# get % total of each row
Biopsy_Res_comb['% Cancer']=round((Biopsy_Res_comb['Cancer'] /
(Biopsy_Res_comb['Cancer']+Biopsy_Res_comb['Healthy']))* 100, 2)
Biopsy_Res_comb['Cancer']=Biopsy_Res_comb['Cancer'].fillna(0)
Biopsy_Res_comb['% Cancer']=Biopsy_Res_comb['% Cancer'].fillna(0)
return Biopsy_Res_comb.style.format("{:,.0f}")
age_biopsy()
age_biopsy = age_biopsy().data; age_biopsy
Bar Graphs¶
age_range_plt = age_biopsy['Total'][0:9]
age_range_plt.plot(kind='bar', width=0.90, figsize=(8,4))
plt.title('Distribution of Female Patients by Age Group')
plt.xlabel('Age of Female'); plt.xticks(rotation = 0)
plt.ylabel('Count'); plt.show()
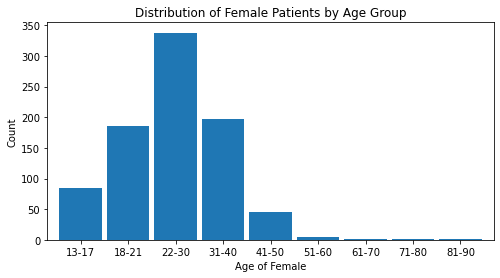
Note. The age range 22-30 has the largest number of observations in this dataset.
fig = plt.figure(figsize=(8,7))
ax1 = fig.add_subplot(211); ax2 = fig.add_subplot(212); fig.tight_layout(pad=6)
age_range_plt2= age_biopsy [['Cancer', 'Healthy']][0:8].sort_values(by=['Cancer'],
ascending=False)
age_range_plt2.plot(kind='bar', stacked=True,
ax=ax1, color = ['#F8766D', '#00BFC4'], width = 0.90)
ax1.set_title('Age Group by Biopsy Results: (Healthy or Cancer)')
ax1.set_xlabel('Age Group'); ax1.set_ylabel('Count')
for tick in ax1.get_xticklabels():
tick.set_rotation(0)
# normalize the plot
age_range_plt_norm = age_range_plt2.div(age_range_plt2.sum(1), axis = 0)
age_range_plt_norm.plot(kind='bar', stacked=True,
ax=ax2,color = ['#F8766D', '#00BFC4'], width = 0.90)
ax2.set_title('Age Group by Biopsy Results: (Healthy or Cancer) - Normalized')
ax2.set_xlabel('Age Group'); ax2.set_ylabel('Frequency')
for tick in ax2.get_xticklabels():
tick.set_rotation(0)
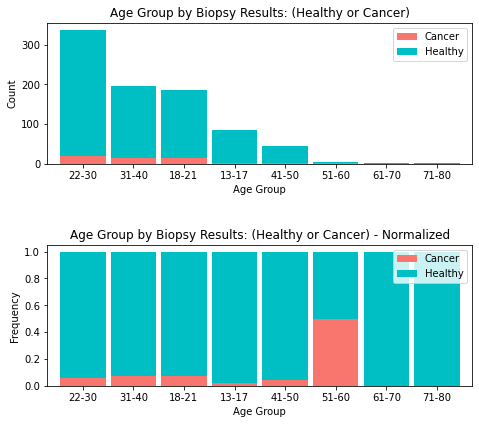
Addressing Multicollinearity¶
# correlation matrix title
print("\033[1m"+'Cervical Cancer Data: Correlation Matrix'+"\033[1m")
# assign correlation function to new variable
corr = cervdat.corr()
matrix = np.triu(corr) # for triangular matrix
plt.figure(figsize=(20,20))
# parse corr variable intro triangular matrix
sns.heatmap(cervdat.corr(method='pearson'),
annot=True, linewidths=.5, cmap="coolwarm", mask=matrix,
square = True,
cbar_kws={'label': 'Correlation Index'})
plt.show()
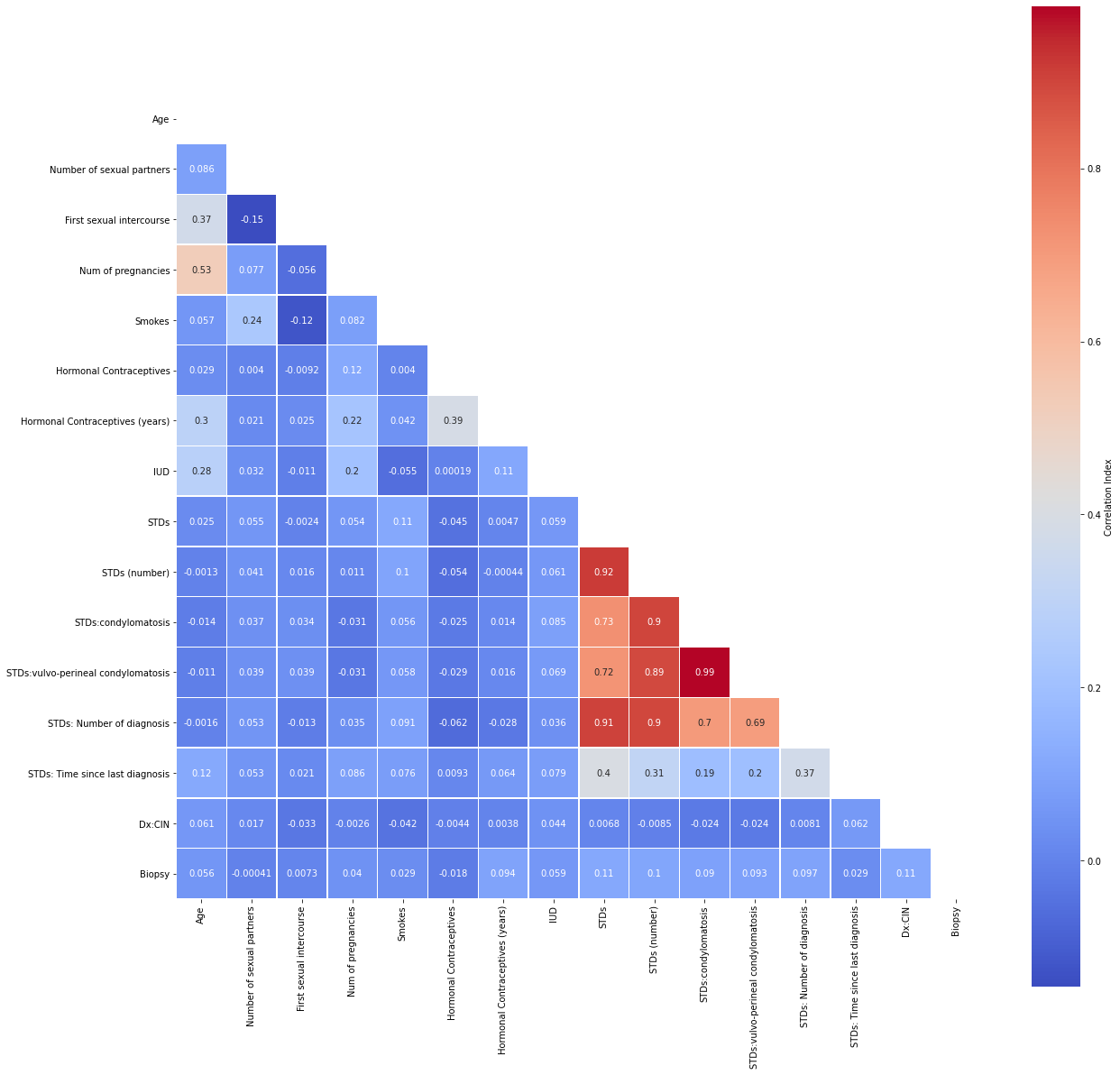
Let us narrow our focus by removing highly correlated predictors and passing the rest into a new dataframe.
cor_matrix = cervdat.corr().abs()
upper_tri = cor_matrix.where(np.triu(np.ones(cor_matrix.shape),
k=1).astype(np.bool))
to_drop = [column for column in upper_tri.columns if
any(upper_tri[column] > 0.75)]
print('These are the columns we should drop: %s'%to_drop)
cervdat1 = cervdat.drop(columns = ['STDs (number)', 'STDs:condylomatosis',
'STDs:vulvo-perineal condylomatosis',
'STDs: Number of diagnosis', 'Age_Range',
'Biopsy_Res'])
cervdat1.shape[1]
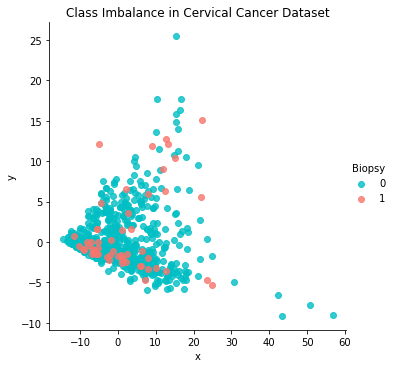
Class Imbalance¶
# biopsy bar graph
biopsy_count = cervdat['Biopsy_Res'].value_counts()
biopsy_count.plot.barh(x ='lab', y='val', rot=0, width=0.99,
color = ['#00BFC4', '#F8766D'], figsize=(8,2))
plt.title ('Biopsy Results by Class')
plt.xlabel('Count'); plt.ylabel('Biopsy Results')
plt.show()
print(biopsy_count)

pca = PCA(n_components=2, random_state=222)
data_2d = pd.DataFrame(pca.fit_transform(cervdat1.iloc[:,0:11]))
data_2d= pd.concat([data_2d, cervdat1['Biopsy']], axis=1)
data_2d.columns = ['x', 'y', 'Biopsy']; data_2d
sns.lmplot('x','y',data_2d,fit_reg=False,hue='Biopsy',palette=['#00BFC4','#F8766D'])
plt.title('Class Imbalance in Cervical Cancer Dataset'); plt.show()
ada = ADASYN(random_state=222)
X_resampled, y_resampled = ada.fit_resample(cervdat1.iloc[:,0:11], cervdat1['Biopsy'])
cervdat2 = pd.concat([pd.DataFrame(X_resampled), pd.DataFrame(y_resampled)], axis=1)
cervdat2.columns = cervdat1.columns
cervdat2['Biopsy'].value_counts()
Checking for Statistical Significance Via Baseline Mode¶
The logistic regression model is introduced as a baseline because establishing impact of coefficients on each independent feature can be carried with relative ease. Moreover, it is possible to gauge statistical significance from the reported p-values of the summary output table below.
Generalized Linear Model - Logistic Regression Baseline
Logistic Regression - Parametric Form
Logistic Regression - Descriptive Form
X1 = cervdat2.drop(columns=['Biopsy'])
X1 = sm.add_constant(X1)
y1 = pd.DataFrame(cervdat2[['Biopsy']])
log_results = sm.Logit(y1,X1, random_state=222).fit()
log_results.summary()
From the summary output table, we observe that Number of sexual partners, First sexual intercourse, Smokes, and Dx:CIN have p-values of 0.588, 0.398, 0.596, and 0.513, respectively, thereby making these variables non-statistically significant where α = 0.05. We will thus remove them from the refined dataset.
cervdat2 = cervdat2.drop(columns=['Number of sexual partners', 'First sexual intercourse', 'Smokes', 'Dx:CIN'])
Train_Test_Split¶
X = cervdat2.drop(columns=['Biopsy'])
y = pd.DataFrame(cervdat2['Biopsy'])
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.20,
random_state=42)
# confirming train_test_split proportions
print('training size:', round(len(X_train)/len(X),2))
print('test size:', round(len(X_test)/len(X),2))
# confirm dimensions (size of newly partioned data)
print('Training:', len(X_train))
print('Test:', len(X_test))
print('Total:', len(X_train) + len(X_test))
Model Building Strategies¶
Logistic Regression¶
from scipy.stats import loguniform
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.model_selection import RandomizedSearchCV
model = LogisticRegression(random_state=222)
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=222)
space = dict()
# define search space
space['solver'] = ['newton-cg', 'lbfgs', 'liblinear']
space['penalty'] = ['none', 'l1', 'l2', 'elasticnet']
space['C'] = loguniform(1e-5, 100)
# define search
search = RandomizedSearchCV(model, space, n_iter=500, scoring='accuracy',
n_jobs=-1, cv=cv, random_state=222)
# execute search
result = search.fit(X_train, y_train)
# summarize result
print('Best Score: %s' % result.best_score_)
print('Best Hyperparameters: %s' % result.best_params_)
# Manually Tuning The Logistic Regression Model
C = [0.01, 0.1, 0.2, 0.5, 0.8, 1, 5, 10, 20, 50]
LRtrainAcc = []
LRtestAcc = []
for param in C:
tuned_lr = LogisticRegression(solver = 'liblinear',
C = param,
max_iter = 500,
penalty = 'l1',
n_jobs = -1,
random_state = 222)
tuned_lr.fit(X_train, y_train)
# Predict on train set
tuned_lr_pred_train = tuned_lr.predict(X_train)
# Predict on test set
tuned_lr1 = tuned_lr.predict(X_test)
LRtrainAcc.append(accuracy_score(y_train, tuned_lr_pred_train))
LRtestAcc.append(accuracy_score(y_test, tuned_lr1))
print('Cost = %2.2f \t Testing Accuracy = %2.2f \t \
Training Accuracy = %2.2f'% (param,accuracy_score(y_test,tuned_lr1),
accuracy_score(y_train,tuned_lr_pred_train)))
# plot cost by accuracy
fig, ax = plt.subplots(figsize=(6,2.5))
ax.plot(C, LRtrainAcc, 'ro-', C, LRtestAcc,'bv--')
ax.legend(['Training Accuracy','Test Accuracy'])
plt.title('Logistic Regression: Accuracy vs. Cost')
ax.set_xlabel('Cost'); ax.set_xscale('log')
ax.set_ylabel('Accuracy'); plt.show()
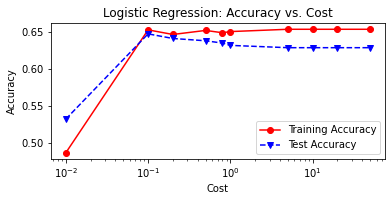
# Un-Tuned Logistic Regression Model
logit_reg = LogisticRegression(random_state=222)
logit_reg.fit(X_train, y_train)
# Predict on test set
logit_reg_pred1 = logit_reg.predict(X_test)
# accuracy and classification report (Untuned Model)
print('Untuned Logistic Regression Model')
print('Accuracy Score')
print(accuracy_score(y_test, logit_reg_pred1))
print('Classification Report \n',
classification_report(y_test, logit_reg_pred1))
# Tuned Logistic Regression Model
tuned_logreg = LogisticRegression(solver = 'liblinear',
C = 0.08,
penalty = 'l1',
max_iter = 500,
n_jobs = -1,
random_state=42)
tuned_logreg.fit(X_train, y_train)
logreg_pred = tuned_logreg.predict(X_test)
# accuracy and classification report (Tuned Model)
print('Tuned Logistic Regression Model')
print('Accuracy Score')
print(accuracy_score(y_test, logreg_pred))
print('Classification Report \n',
classification_report(y_test, logreg_pred))
Random Forest¶
model_params = {
# randomly sample numbers from 4 to 204 estimators
'n_estimators': randint(4,200),
# normally distributed max_features,
# with mean .25 stddev 0.1, bounded between 0 and 1
'max_features': truncnorm(a=0, b=1, loc=0.25, scale=0.1),
# uniform distribution from 0.01 to 0.2 (0.01 + 0.199)
'min_samples_split': uniform(0.01, 0.199)
}
# create random forest classifier model
rf_model = RandomForestClassifier()
# set up random search meta-estimator
# this will train 100 models over 5 folds of cross validation
# (500 models total)
clf = RandomizedSearchCV(rf_model, model_params, n_iter=100,
cv=5, scoring='accuracy', random_state=222)
# train the random search meta-estimator to find the
# best model out of 100 candidates
result2 = clf.fit(X_train, y_train)
# print winning set of hyperparameters
from pprint import pprint
print('Best Score: %s' % result2.best_score_)
pprint(result2.best_estimator_.get_params())
# Random Forest Tuning (Manual)
rf_train_accuracy = []
rf_test_accuracy = []
for n in range(1, 15):
rf = RandomForestClassifier(max_depth = n,
random_state=222)
rf = rf.fit(X_train, y_train)
rf_pred_train = rf.predict(X_train)
rf_pred_test = rf.predict(X_test)
rf_train_accuracy.append(accuracy_score(y_train,
rf_pred_train))
rf_test_accuracy.append(accuracy_score(y_test,
rf_pred_test))
print('Max Depth = %2.0f \t Test Accuracy = %2.2f \t \
Training Accuracy = %2.2f'% (n, accuracy_score(y_test,
rf_pred_test),
accuracy_score(y_train,
rf_pred_train)))
max_depth = list(range(1, 15))
fig, plt.subplots(figsize=(6,2.5))
plt.plot(max_depth, rf_train_accuracy, 'bv--',
label='Training Accuracy')
plt.plot(max_depth, rf_test_accuracy, 'ro--',
label='Test Accuracy')
plt.title('Random Forest Accuracy')
plt.xlabel('Depth')
plt.ylabel('Accuracy')
plt.xticks(max_depth)
plt.legend()
plt.show()
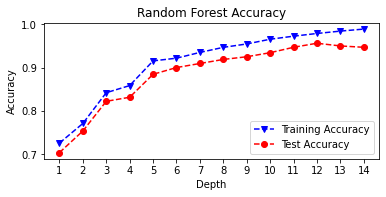
# Untuned Random Forest
untuned_rf = RandomForestClassifier(random_state=222)
untuned_rf = untuned_rf.fit(X_train, y_train)
# Predict on test set
untuned_rf1 = untuned_rf.predict(X_test)
# accuracy and classification report
print('Untuned Random Forest Model')
print('Accuracy Score')
print(accuracy_score(y_test, untuned_rf1))
print('Classification Report \n',
classification_report(y_test, untuned_rf1))
# Tuned Random Forest
tuned_rf = RandomForestClassifier(random_state=222,
max_depth = 12)
tuned_rf = tuned_rf.fit(X_train, y_train)
# Predict on test set
tuned_rf1 = tuned_rf.predict(X_test)
# accuracy and classification report
print('Tuned Random Forest Model')
print('Accuracy Score')
print(accuracy_score(y_test, tuned_rf1))
print('Classification Report \n',
classification_report(y_test, tuned_rf1))
Support Vector Machines¶
Similar to that of logistic regression, a linear support vector machine model relies on estimating $(w^*,b^*)$ visa vie constrained optimization of the following form:
\begin{eqnarray*} &&\min_{w^*,b^*,\{\xi_i\}} \frac{\|w\|^2}{2} + \frac{1}{C} \sum_i \xi_i \\ \textrm{s.t.} && \forall i: y_i\bigg[w^T \phi(x_i) + b\bigg] \ge 1 - \xi_i, \ \ \xi_i \ge 0 \end{eqnarray*}However, our endeavor relies on the radial basis function kernel:
$$ K(x,x^{'}) = \text{exp} \left(-\frac{||x-x^{'}||^2}{2\sigma^2} \right) $$where $||x-x^{'}||^2$ is the squared Euclidean distance between the two feature vectors, and $\gamma = \frac{1}{2\sigma^2}$.
Simplifying the equation we have:
$$ K(x,x^{'}) = \text{exp} (-\gamma ||x-x^{'}||^2) $$SVM (Radial Basis Function) Model¶
svm1 = SVC(kernel='rbf', random_state=222)
svm1.fit(X_train, y_train)
svm1_pred_test = svm1.predict(X_test)
print('accuracy = %2.2f ' % accuracy_score(y_test, svm1_pred_test))
Setting (tuning) the gamma hyperparameter to "auto"¶
svm2 = SVC(kernel='rbf', gamma='auto', random_state=222)
svm2.fit(X_train, y_train)
svm2_pred_test = svm2.predict(X_test)
print('accuracy = %2.2f ' % accuracy_score(svm2_pred_test,y_test))
C = [0.01, 0.1, 0.2, 0.5, 0.8, 1, 5, 10, 20, 50]
svm3_trainAcc = []
svm3_testAcc = []
for param in C:
svm3 = SVC(C=param,kernel='rbf', gamma = 'auto', random_state=42)
svm3.fit(X_train, y_train)
svm3_pred_train = svm3.predict(X_train)
svm3_pred_test = svm3.predict(X_test)
svm3_trainAcc.append(accuracy_score(y_train, svm3_pred_train))
svm3_testAcc.append(accuracy_score(y_test, svm3_pred_test))
print('Cost = %2.2f \t Testing Accuracy = %2.2f \t \
Training Accuracy = %2.2f'% (param,accuracy_score(y_test,svm3_pred_test),
accuracy_score(y_train,svm3_pred_train)))
fig, ax = plt.subplots()
ax.plot(C, svm3_trainAcc, 'ro-', C, svm3_testAcc,'bv--')
ax.legend(['Training Accuracy','Test Accuracy'])
plt.title('SVM with Varying Costs - Accuracy vs. Cost')
ax.set_xlabel('C')
ax.set_xscale('log')
ax.set_ylabel('Accuracy')
plt.show()
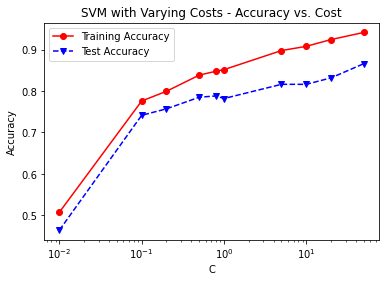
# Untuned Support Vector Machine
untuned_svm = SVC(random_state=222)
untuned_svm = untuned_svm.fit(X_train, y_train)
# Predict on test set
untuned_svm1 = untuned_svm.predict(X_test)
# accuracy and classification report
print('Untuned Support Vector Machine Model')
print('Accuracy Score')
print(accuracy_score(y_test, untuned_svm1))
print('Classification Report \n',
classification_report(y_test, untuned_svm1))
# Tuned Support Vector Machine
tuned_svm = SVC(kernel='rbf',
gamma='auto',
random_state=222,
C = 50, probability = True)
tuned_svm = tuned_svm.fit(X_train, y_train)
# Predict on test set
tuned_svm1 = tuned_svm.predict(X_test)
# accuracy and classification report
print('Tuned Support Vector Machine Model')
print('Accuracy Score')
print(accuracy_score(y_test, tuned_svm1))
print('Classification Report \n',
classification_report(y_test, tuned_svm1))
Model Evaluation¶
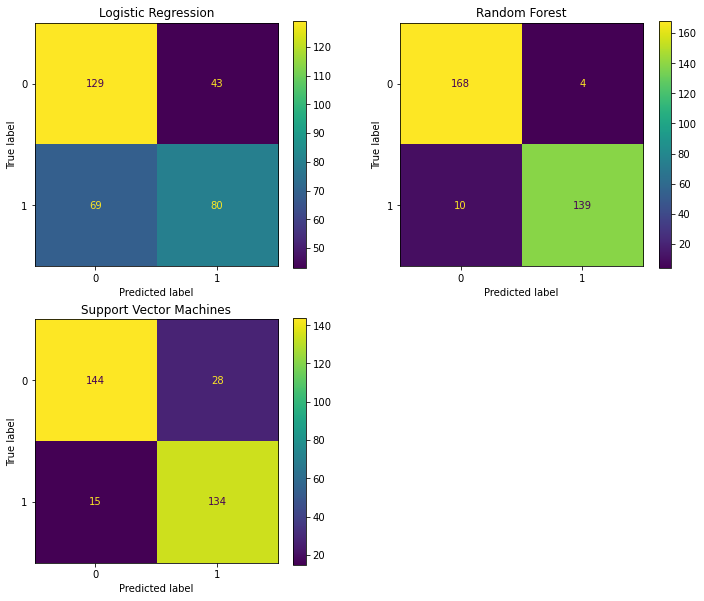
Confusion Matrices¶
fig = plt.figure(figsize=(12,10))
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(222)
ax3 = fig.add_subplot(223)
# logistic regression confusion matrix
plot_confusion_matrix(tuned_logreg, X_test, y_test, ax=ax1)
ax1.set_title('Logistic Regression')
# Decision tree confusion matrix
plot_confusion_matrix(tuned_rf, X_test, y_test, ax=ax2)
ax2.set_title('Random Forest')
# random forest confusion matrix
plot_confusion_matrix(tuned_svm, X_test, y_test, ax=ax3)
ax3.set_title('Support Vector Machines')
plt.show()
ROC Curves¶
lr_pred = tuned_logreg.predict_proba(X_test)[:, 1]
rf_pred = tuned_rf.predict_proba(X_test)[:, 1]
svm_pred = tuned_svm.predict_proba(X_test)[:, 1]
# plot all of the roc curves on one graph
tuned_lr_roc = metrics.roc_curve(y_test,lr_pred)
fpr,tpr,thresholds = metrics.roc_curve(y_test,lr_pred)
tuned_lr_auc = metrics.auc(fpr, tpr)
tuned_lr_plot = metrics.RocCurveDisplay(fpr=fpr,tpr=tpr,
roc_auc = tuned_lr_auc,
estimator_name = 'Logistic Regression')
tuned_rf1_roc = metrics.roc_curve(y_test,rf_pred)
fpr,tpr,thresholds = metrics.roc_curve(y_test,rf_pred)
tuned_rf1_auc = metrics.auc(fpr, tpr)
tuned_rf1_plot = metrics.RocCurveDisplay(fpr=fpr,tpr=tpr,
roc_auc=tuned_rf1_auc,
estimator_name = 'Random Forest')
tuned_svm1_roc = metrics.roc_curve(y_test, svm_pred)
fpr,tpr,thresholds = metrics.roc_curve(y_test,svm_pred)
tuned_svm1_auc = metrics.auc(fpr, tpr)
tuned_svm1_plot = metrics.RocCurveDisplay(fpr=fpr,tpr=tpr,
roc_auc=tuned_svm1_auc,
estimator_name = 'Support Vector Machines')
# plot set up
fig, ax = plt.subplots(figsize=(8,5))
plt.title('ROC Curves for 3 Models',fontsize=12)
plt.plot([0, 1], [0, 1], linestyle = '--',
color = '#174ab0')
plt.xlabel('',fontsize=12)
plt.ylabel('',fontsize=12)
# Model ROC Plots Defined above
tuned_lr_plot.plot(ax)
tuned_rf1_plot.plot(ax)
tuned_svm1_plot.plot(ax)
plt.show()
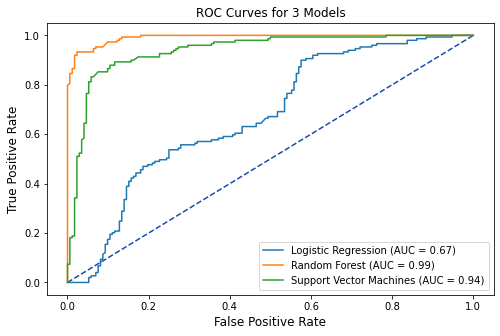
Performance Metrics¶
# Logistic Regression Performance Metrics
report1 = classification_report(y_test, logreg_pred, output_dict=True)
accuracy1 = round(report1['accuracy'],4)
precision1 = round(report1['1']['precision'],4)
recall1 = round(report1['1']['recall'],4)
fl_score1 = round(report1['1']['f1-score'],4)
# Decision Tree Performance Metrics
report2 = classification_report(y_test,tuned_rf1, output_dict=True)
accuracy2 = round(report2['accuracy'],4)
precision2 = round(report2['1']['precision'],4)
recall2 = round(report2['1']['recall'],4)
fl_score2 = round(report2['1']['f1-score'],4)
# Random Forest Performance Metrics
report3 = classification_report(y_test,tuned_svm1,output_dict=True)
accuracy3 = round(report3['accuracy'],4)
precision3 = round(report3['1']['precision'],4)
recall3 = round(report3['1']['recall'],4)
fl_score3 = round(report3['1']['f1-score'],4)
table1 = PrettyTable()
table1.field_names = ['Model', 'Test Accuracy',
'Precision', 'Recall',
'F1-score']
table1.add_row(['Logistic Regression', accuracy1,
precision1, recall1, fl_score1])
table1.add_row(['Random Forest', accuracy2,
precision2, recall2, fl_score2])
table1.add_row(['Support Vector Machines', accuracy3,
precision3, recall3, fl_score3])
print(table1)
# Mean-Squared Errors
mse1 = round(mean_squared_error(y_test, logreg_pred),4)
mse2 = round(mean_squared_error(y_test, tuned_rf1),4)
mse3 = round(mean_squared_error(y_test, tuned_svm1),4)
table2 = PrettyTable()
table2.field_names = ['Model', 'AUC', 'MSE']
table2.add_row(['Logistic Regression',
round(tuned_lr_auc,4), mse1])
table2.add_row(['Random Forest',
round(tuned_rf1_auc,4), mse2])
table2.add_row(['Support Vector Machines',
round(tuned_svm1_auc,4), mse3])
print(table2)
References
Brownlee, J. (2020, July 24). Train-Test Split for Evaluating Machine Learning Algorithms. Machine Learning Mastery. https://machinelearningmastery.com/train-test-split-forevaluating-machine-learning-algorithms/
Centers for Disease Control and Prevention. (2021, January 12). What Are the Risk Factors for Cervical Cancer? https://www.cdc.gov/cancer/cervical/basic_info/risk_factors.htm
Dua, D., & Graff, C. (2019). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science. https://archive.ics.uci.edu/ml/datasets/Cervical+cancer+%28Risk+Factors%29
Kelwin F., Cardoso, J.S., and Fernandes, J. (2017). Transfer Learning with Partial Observability Applied to Cervical Cancer Screening. Springer International Publishing, 1055, 243-250. https://www.doi.org/10.1007/978-3-319-58838-4_27
Kuhn, M., & Johnson, K. (2016). Applied Predictive Modeling. Springer. https://doi.org/10.1007/978-1-4614-6849-3
Kuhn, M. (2019, March 27). Subsampling For Class Imbalances. Github. https://topepo.github.io/caret/subsampling-for-class-imbalances.html
World Health Organization. (2021). IARC marks Cervical Cancer Awareness Month 2021. https://www.iarc.who.int/news-events/iarc-marks-cervical-cancer-awareness-month-2021/