Exploratory Data Analysis - Phase II¶
Team Members: Leonid Shpaner, Christopher Robinson, and Jose Luis Estrada
This notebook takes a more granular look into the columns of interest using boxplots, stacked bar graphs, histograms, and culminates with a correlation matrix.
from google.colab import drive
drive.mount('/content/drive', force_remount=True)
%cd /content/drive/Shared drives/Capstone - Best Group/GitHub Repository/navigating_crime/Code Library
####################################
## import the requisite libraries ##
####################################
import os
import csv
import pandas as pd
import numpy as np
# plotting libraries
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
# suppress warnings for cleaner output
warnings.filterwarnings('ignore')
# suppress future warnings for cleaner output
warnings.filterwarnings(action='ignore', category=FutureWarning)
# check current working directory
current_directory = os.getcwd()
current_directory
Assign Paths to Folders¶
# path to the data file
data_frame = '/content/drive/Shareddrives/Capstone - Best Group/' \
+ 'Final_Data_20220719/df.csv'
# path to data folder
data_folder = '/content/drive/Shareddrives/Capstone - Best Group/' \
+ 'GitHub Repository/navigating_crime/Data Folder/'
# path to the training file
train_path = '/content/drive/Shareddrives/Capstone - Best Group/' \
+ 'GitHub Repository/navigating_crime/Data Folder/train_set.csv'
# path to the image library
eda_image_path = '/content/drive/Shareddrives/Capstone - Best Group/' \
+ 'GitHub Repository/navigating_crime/Image Folder/EDA Images'
# bring in original dataframe as preprocessed in the
# data_preparation.ipynb file
df = pd.read_csv(data_frame, low_memory=False).set_index('OBJECTID')
# re-inspect the shape of the dataframe.
print('There are', df.shape[0], 'rows and', df.shape[1],
'columns in the dataframe.')
Age Range Statistics¶
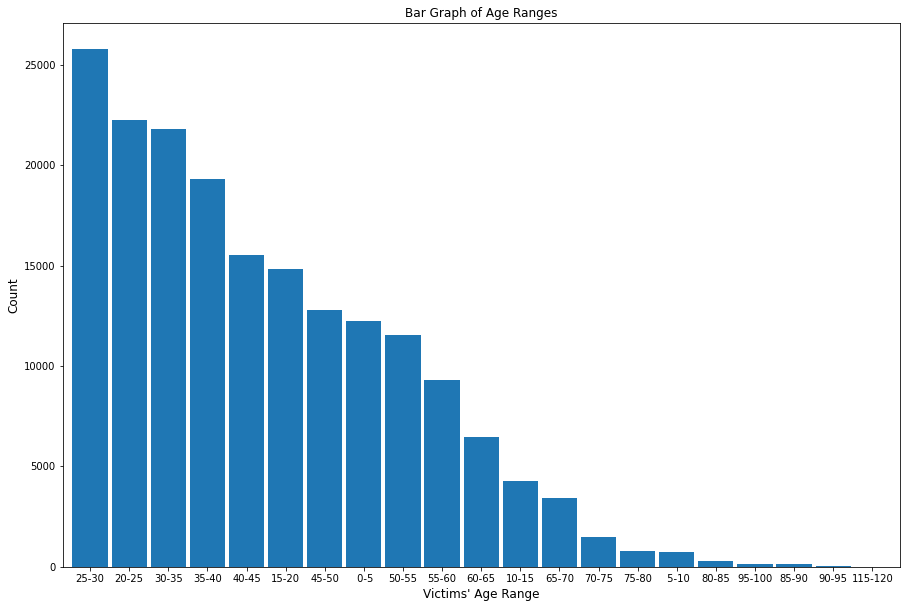
The top three ages of crime victims are 25-30, 20-25, and 30-35, with ages 25-30 reporting 25,792 crimes, ages 20-25 reporting 22,235 crimes, and ages 30-35 reporting 21,801 crimes, respectively.
# this bar_plot library was created as a bar_plot.py file during the EDA Phase I
# stage; it can be acccessed in that respective notebook
from functions import bar_plot
bar_plot(15, 10, df, False, 'bar', 'Bar Graph of Age Ranges', 0,
"Victims' Age Range", 'Count', 'age_bin', 100)
plt.savefig(eda_image_path + '/age_range_bargraph.png', bbox_inches='tight')
Contingency Table¶
Using a contingency table allows for the data in any column of interest to be summarized by the values in the target column (crime severity).
from functions import cont_table
Summary Statistics¶
Calling this from the functions.py library will provide summary statistics for any column in the dataframe.
from functions import summ_stats
Status Description by Age¶
summ_stats(df, 'Status_Desc', 'Vict_Age')
Victim Sex by Age¶
summ_stats(df, 'Victim_Sex', 'Vict_Age')
Stacked Bar Plots¶
This function provides a stacked and normalized bar graph of any column of interest, colored by ground truth column
from functions import stacked_plot
Crime Severity by Age Group¶
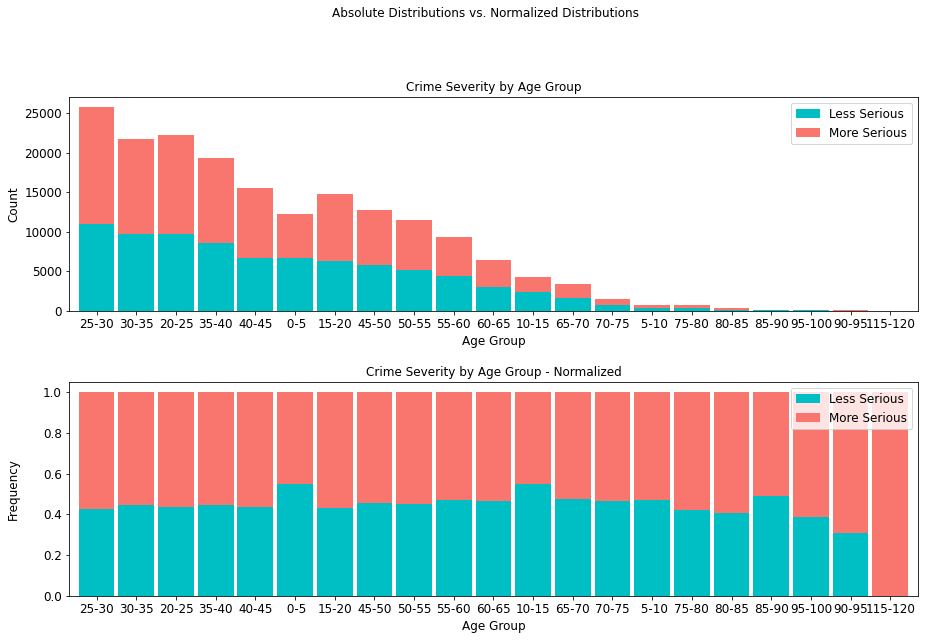
Crime severity presents at an about even ratio per age group, with the exception being the highest age range of 115-120, where crime incidence is lower, but overall, more serious. Moreover, it is interesting to note that there are 19,073 more serious crimes than less serious ones, comprising an overwhelming majority (55.56%) of all cases.
age_table = cont_table(df, 'crime_severity', 'Less Serious', 'age_bin',
'More Serious').data
age_table
stacked_plot(15, 10, 10, df, 'age_bin', 'crime_severity', 'Less Serious', 'bar',
'Crime Severity by Age Group', 'Age Group', 'Count', 0.9, 0,
'Crime Severity by Age Group - Normalized', 'Age Group',
'Frequency')
plt.savefig(eda_image_path + '/age_crime_stacked_bar.png', bbox_inches='tight')
Crime Severity by Street Type¶
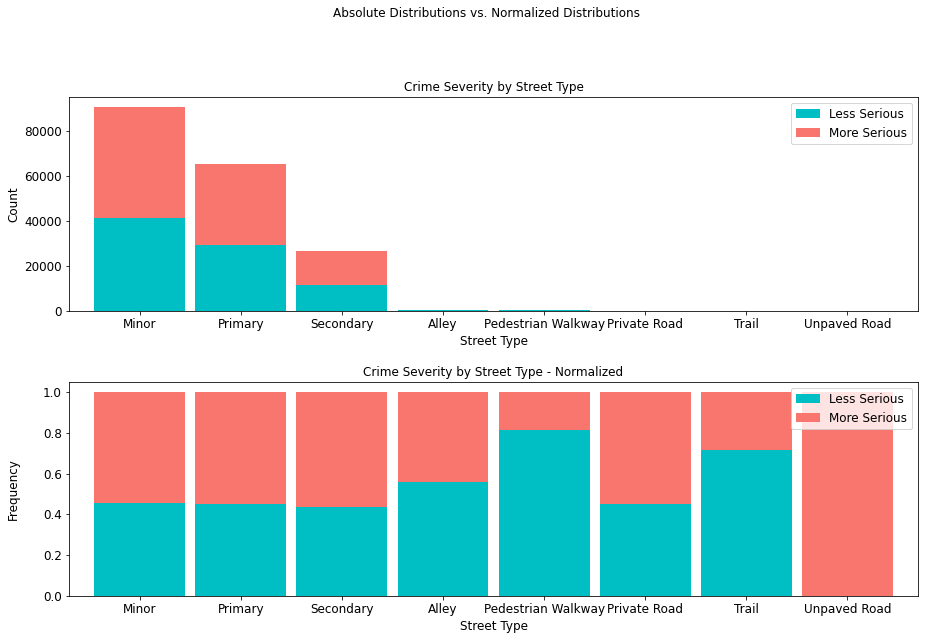
It is interesting to note that not only the least serious crimes occur in alleys, pedestrian walkways, private roads (paved or unpaved), and trails, but that where they do occur, they are less severe.
street_type_table = cont_table(df, 'crime_severity', 'Less Serious',
'Type', 'More Serious').data
street_type_table
stacked_plot(15, 10, 10, df, 'Type', 'crime_severity', 'Less Serious', 'bar',
'Crime Severity by Street Type', 'Street Type', 'Count', 0.9, 0,
'Crime Severity by Street Type - Normalized', 'Street Type',
'Frequency')
plt.savefig(eda_image_path + '/streettype_stacked_bar.png', bbox_inches='tight')
Crime Severity by Sex¶
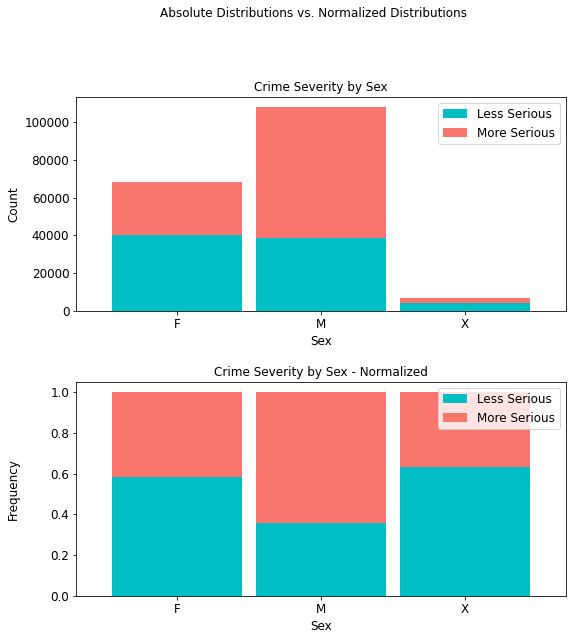
Whereas there are more males than females in this dataset, it can be seen from both the regular and normalized distributions, respectively, that more serious crimes occur with a higher prevalence (69,370 or 64.24%) for the former than the latter (28,565 or 41.70%). For sexes unknown, there is a 36.70% prevalence rate for more serious crimes.
sex_table = cont_table(df, 'crime_severity', 'Less Serious', 'Victim_Sex',
'More Serious').data
sex_table
stacked_plot(10, 10, 10, df, 'Victim_Sex', 'crime_severity', 'Less Serious',
'bar', 'Crime Severity by Sex', 'Sex', 'Count',
0.9, 0, 'Crime Severity by Sex - Normalized', 'Sex', 'Frequency')
plt.savefig(eda_image_path + '/victim_sex_stacked_bar.png', bbox_inches='tight')
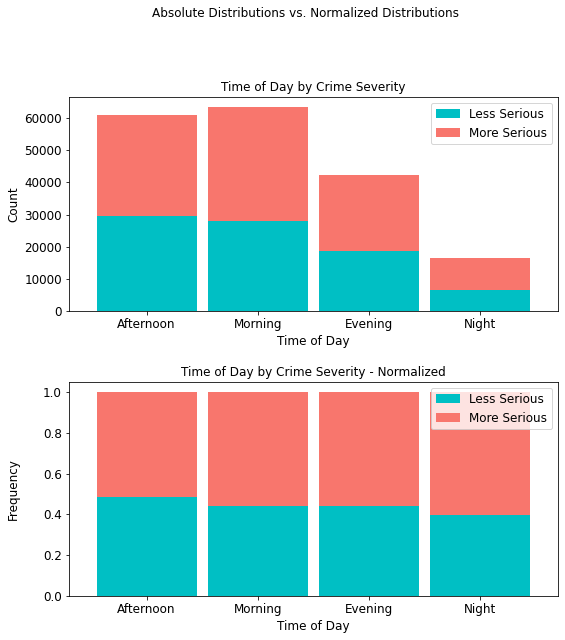
Crime Severity by Time of Day¶
It is interesting to note that more serious crimes (35,396) occur in the morning than any other time of day, with more serious night crimes accounting for only 9,814 (approximately 10%) of all such crimes.
time_table = cont_table(df, 'crime_severity', 'Less Serious',
'Time_of_Day', 'More Serious').data
time_table
stacked_plot(10, 10, 10, df, 'Time_of_Day', 'crime_severity', 'Less Serious',
'bar', 'Time of Day by Crime Severity', 'Time of Day', 'Count',
0.9, 0, 'Time of Day by Crime Severity - Normalized',
'Time of Day', 'Frequency')
plt.savefig(eda_image_path + '/time_day_stacked_bar.png', bbox_inches='tight')
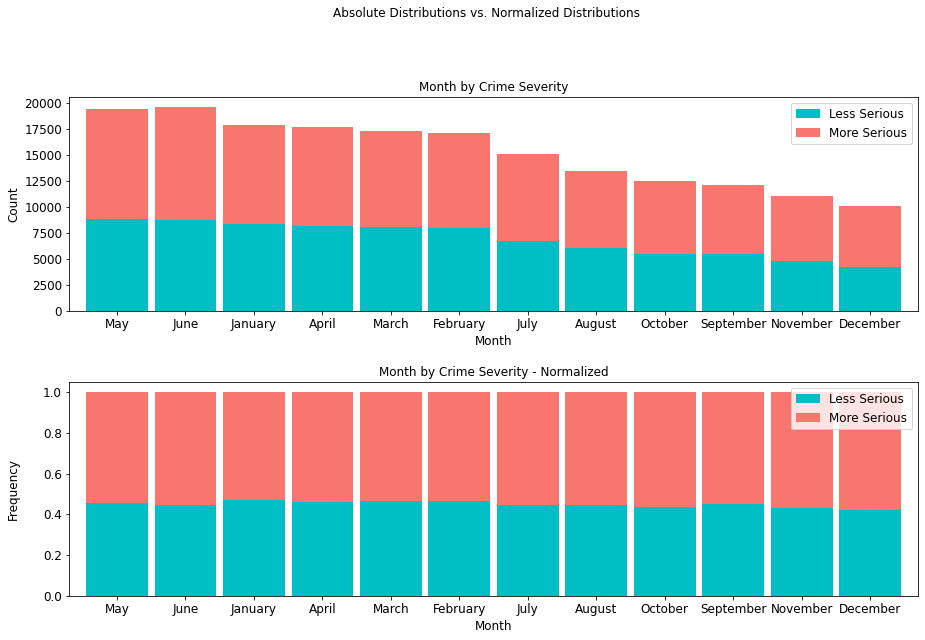
Crime Severity by Month¶
The month of June presents a record of 10,852 more serious crimes than any other month, so there exists a higher prevalence of more serious crimes mid-year than any other time of year.
month_table = cont_table(df, 'crime_severity', 'Less Serious',
'Month', 'More Serious').data
month_table
stacked_plot(15, 10, 10, df, 'Month', 'crime_severity', 'Less Serious',
'bar', 'Month by Crime Severity', 'Month', 'Count',
0.9, 0, 'Month by Crime Severity - Normalized',
'Month', 'Frequency')
plt.savefig(eda_image_path + '/month_stacked_bar.png', bbox_inches='tight')
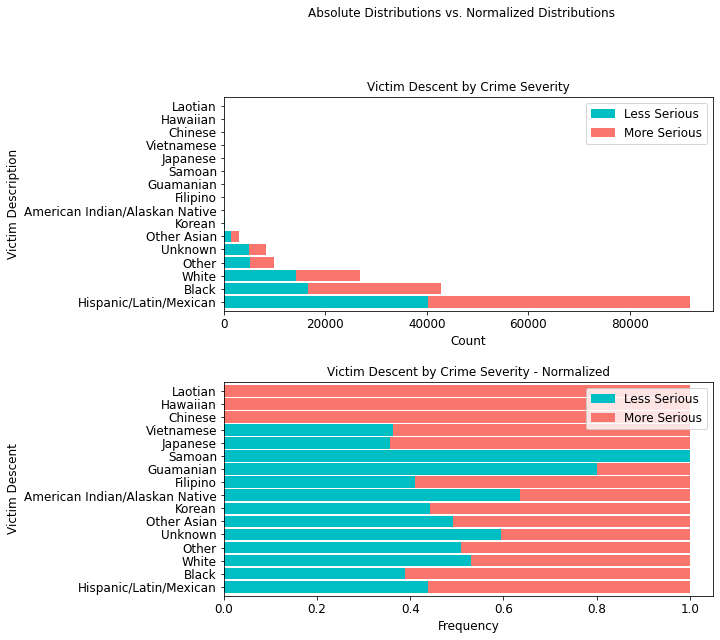
Crime Severity Victim Descent¶
In terms of ethnicity, members of the Hispanic/Latin/Mexican demographic account for 51,601 incidences of more serious crimes. More importantly, with an additional 40,226 less serious crimes, this demographic accounts for a total of 91,827 crimes, an overwhelming 50% of all crimes in the data.
descent_table = cont_table(df, 'crime_severity', 'Less Serious',
'Victim_Desc', 'More Serious').data
descent_table
stacked_plot(10,10, 10, df, 'Victim_Desc', 'crime_severity', 'Less Serious',
'barh', 'Victim Descent by Crime Severity', 'Count',
'Victim Description', 0.9, 0,
'Victim Descent by Crime Severity - Normalized',
'Frequency', 'Victim Descent')
plt.savefig(eda_image_path + '/victim_desc_stacked_bar.png', bbox_inches='tight')
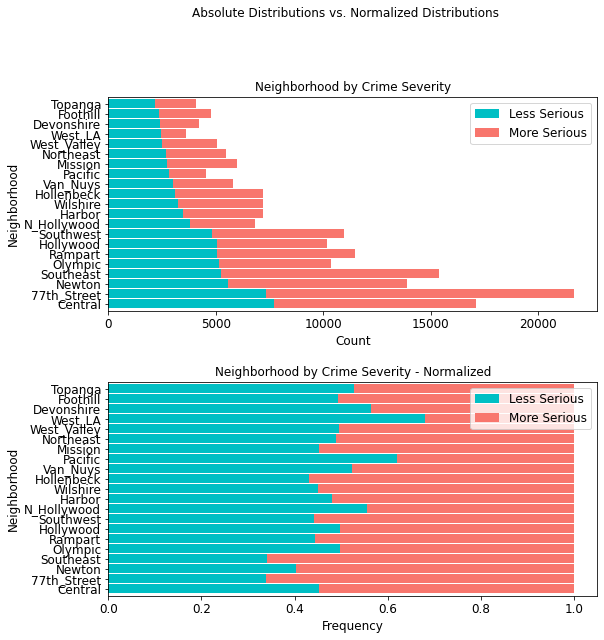
Crime Severity by Neighborhood¶
In terms of neighborhoods based on police districts, the 77th Street region shows the highest amount of more serious crimes (14,350) than any other district; second is the Southeast area (10,142).
area_table = cont_table(df, 'crime_severity', 'Less Serious',
'AREA_NAME', 'More Serious').data
area_table
stacked_plot(10, 10, 10, df, 'AREA_NAME', 'crime_severity', 'Less Serious',
'barh', 'Neighborhood by Crime Severity', 'Count', 'Neighborhood',
0.9, 0, 'Neighborhood by Crime Severity - Normalized', 'Frequency',
'Neighborhood')
plt.savefig(eda_image_path + '/area_stacked_bar.png', bbox_inches='tight')
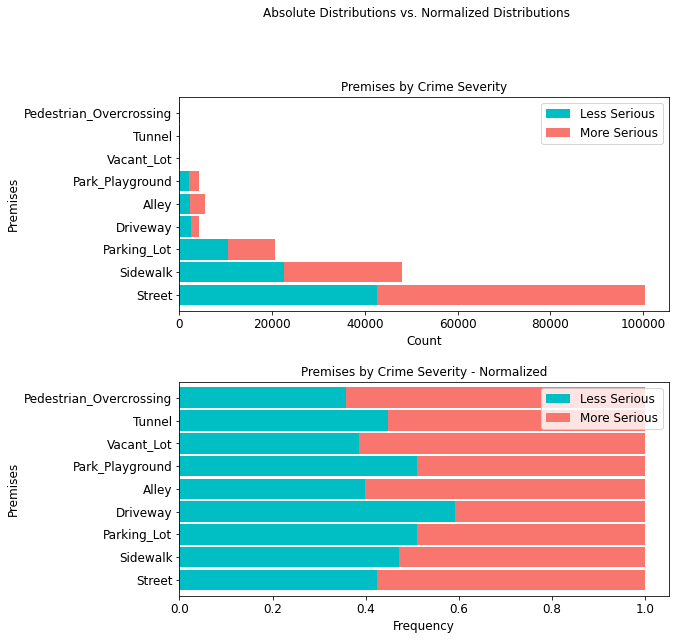
Crime Severity by Premises¶
It is equally important to note that most crimes (100,487 or ~55%) occur on the street, with 57.51% being attributed to more serious crimes.
premis_table = cont_table(df, 'crime_severity', 'Less Serious',
'Premises', 'More Serious').data
premis_table
stacked_plot(10, 10, 10, df, 'Premises', 'crime_severity', 'Less Serious', 'barh',
'Premises by Crime Severity', 'Count', 'Premises', 0.9, 0,
'Premises by Crime Severity - Normalized', 'Frequency',
'Premises')
plt.savefig(eda_image_path + '/premises_stacked_bar.png', bbox_inches='tight')
Histogram Distributions Colored by Crime Code Target¶
# read in the train set since we are inspecting ground truth only on this subset
# to avoid exposing information from the unseen data
train_set = pd.read_csv(train_path).set_index('OBJECTID')
# Histogram Distributions Colored by Crime Code Target
def colored_hist(target, nrows, ncols, x, y, w_pad, h_pad):
'''
This function shows a histogram for the entire dataframe, colored by
the ground truth column.
Inputs:
target: ground truth column
nrows: number of histogram rows to include in plot
ncols: number of histogram cols to include in plot
x: x-axis figure size
y: y-axis figure size
w_pad: width padding for plot
h_pad: height padding for plot
'''
# create empty list to enumerate columns from
list1 = train_set.drop(columns={target})
# set the plot size dimensions
fig, axes = plt.subplots(nrows, ncols, figsize=(x, y))
ax = axes.flatten()
for i, col in enumerate(list1):
train_set.pivot(columns=target)[col].plot(kind='hist', density=True,
stacked=True, ax=ax[i])
ax[i].set_title(col)
ax[i].set_xlabel('Values')
ax[i].legend(loc='upper right')
fig.tight_layout(w_pad=w_pad, h_pad=h_pad)
colored_hist('Crime_Code', 5, 7, 25, 20, 6, 12)
plt.savefig(eda_image_path + '/colored_hist.png', bbox_inches='tight')

Examining Possible Correlations¶
# this function is defined and used only once; hence, it remains in
# this notebook
def corr_plot(df, x, y):
'''
This function plots a correlation matrix for the dataframe
Inputs:
df: dataframe to ingest into the correlation matrix plot
x: x-axis size
y: y-axis size
'''
# correlation matrix title
print("\033[1m" + 'La Crime Data: Correlation Matrix'
+ "\033[1m")
# assign correlation function to new variable
corr = df.corr()
matrix = np.triu(corr) # for triangular matrix
plt.figure(figsize=(x,y))
# parse corr variable intro triangular matrix
sns.heatmap(df.corr(method='pearson'),
annot=True, linewidths=.5, cmap='coolwarm', mask=matrix,
square=True,
cbar_kws={'label': 'Correlation Index'})
# subset train set without index into new corr_df dataframe
corr_df = train_set.reset_index(drop=True)
# plot the correlation matrix
corr_plot(corr_df, 25, 25)
plt.savefig(eda_image_path + '/correlation_plot.png', bbox_inches='tight')
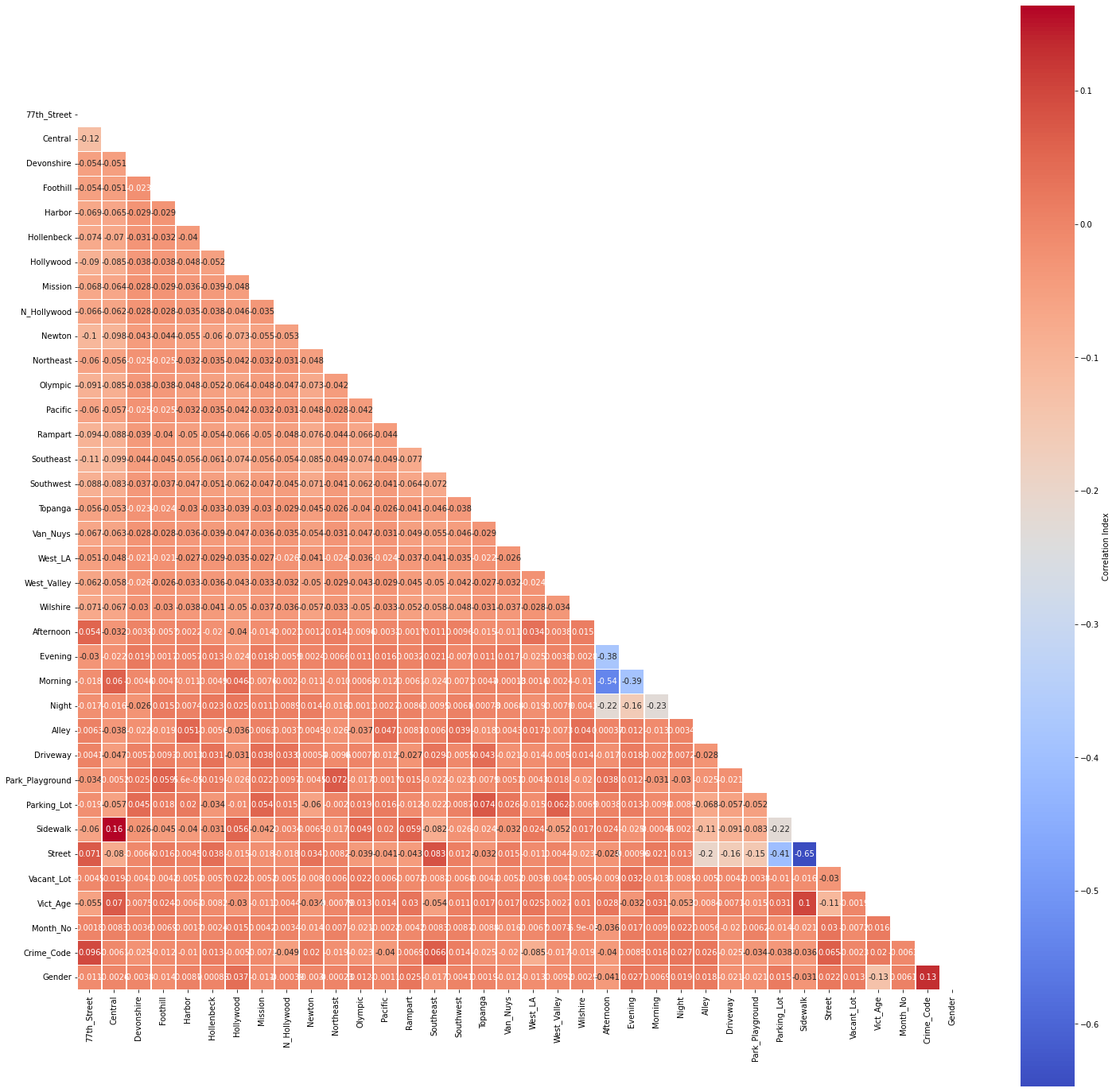
No multicollinearity has been detected at a threshold of r=0.75.